Sophie Hagman och hennes samtida by Carl Forsstrand : Difficulty Assessment for Swedish Learners
How difficult is Sophie Hagman och hennes samtida for Swedish learners? We have performed multiple tests on its full text (freely available here) of approximately 53,286, crunched all the numbers for you and present the results below.
Read the Full Text Now for Free!
Difficulty Assessment Summary
We have estimated Sophie Hagman och hennes samtida to have a difficulty score of 84. Here're its scores:
| Measure | Score | |
|---|---|---|
| easy difficult | (1 - 100) | |
| Overall Difficulty | 84 | |
| Vocabulary Difficulty | 92 | |
| Grammatical Difficulty | 76 |
Vocabulary Difficulty: Breakdown
Vocabulary difficulty: 92%
This score has been calculated based on frequency vocabulary (the top most frequently used words in Swedish). It combines various measures of Sophie Hagman och hennes samtida's text analyzed in terms of frequency vocabulary: a plain vocabulary score, frequency-weighted vocabulary score, banded frequency vocabulary scores based on vocabulary of the text falling in the top 1,000 or 2,000 most frequent words, etc. Here's a further breakdown of how often the top most frequently used words in Swedish appear in the full text of Sophie Hagman och hennes samtida:

We have also calculated the following approximate data on the vocabulary in Sophie Hagman och hennes samtida:
| Measure | Score |
|---|---|
| Measure | Score |
| Number of words | 53,286 |
| Number of unique words | 10,897 |
| Number of recognized words for names/places/other entities | 3,899 |
| Number of very rare non-entity words | 5,885 |
| Number of sentences | 2,648 |
| Average number of words/sentence | 20 |
There is some research suggesting that that you need to know about 98% of a text's vocabulary in order to be able to infer the meaning of unknown words when reading. If true, this means that you would need to know around 10,679 words (where all the forms of the word are still counted as unique words) in Swedish to be able to read Sophie Hagman och hennes samtida without a dictionary and fully understand it.
Grammatical Difficulty: Breakdown
Grammatical difficulty: 76%
Here is the further grammatical comparison on this text. You can find an explanation of all these scores below.
| Measure | Score |
|---|---|
| Measure | Score |
| Automated Readability Index | 14 |
| Coleman-Liau Index | 14 |
| Type/Token Ratio (TTR) | 0.2045 |
| Root type/Token Ratio (RTTR) | 0.00000383779 |
| Corrected type/Token Ratio (CTTR) | 0.00000191889 |
| MTLD Index | 79 |
| HDD Index | 71 |
| Yule's I Index | 90 |
| Lexical Diversity Index (MTLD + HD-D + Yule's I) | 80 |
The type-token ratio (TTR) of Sophie Hagman och hennes samtida is 0.2045. The TTR is the most basic measure of lexical diversity. To calculate it, we divide the number of unique words by the number of words in the text. For example, for this text, the number of unique words is 10,897, while the number of words is 53,286, so the TTR is 10,897 / 53,286 = 0.2045. However, the TTR is a very crude measure, as it is extremely dependent on text length. The longer the text, the lower the TTR is usually going to be, since common words tend to often repeat. Especially since the number of words in this text is more than 1,000, the TTR is not likely to give an accurate measure.
The root type-token ratio (RTTR) and corrected type-token ratio (CTTR) are measures which were suggested by researchers to partially address the problem of TTR's variance on text length. In the RTTR, the number of unique words is divided by a square of the number of words (therefore, 10,897 / (53,286 * 53,286) = 0.00000383779), while in CTTR, it is divided by a square of the number of words, multiplied twice 10,897 / 2 * (53,286 * 53,286) = 0.00000191889). However, these measures are not as easily readable, and also there is a growing body of research asserting that CTTR and RTTR do not effectively address the problems of text length. Therefore, while we do provide the full text's TTR, RTTR and CTTR on this page, these fiqures do not form part of our final calculations.
The Automated Readability Index (ARI) is one readability measure that has been developed by researchers over the years. The formula for calculating the ARI is as follows: 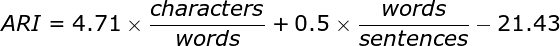
The ARI should compute a reading level approximately corresponding to the reader's grade level (assuming the reader undertakes formal education). Thus, for example, a value of 1 is kindergarten level, while a value of 12 or 13 is the last year of school, and 14 is a sophomore at college. The current ARI of this text is 14, making it understandable for 14-grade students at their expected level of education.
The Coleman Liau Index (CLI) is a similar index designed by Meri Coleman and T. L. Liau, and it is supposed to compute the grade level of the reader (thus, for example, sophomore level material would be around grade 14, or year 14 of formal education, while kindergarten / primary school level material would be close to grade 1 in the CLI). The CLI is usually slightly higher than the ARI. The CLI is computed with this formula:
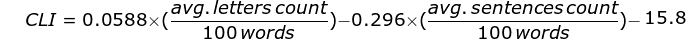
It is notable that other indexes exist, such as the Flesch-Kincaid Reading Ease, Gunning-Fog Score, and others, but we have chosen not to include them, since, contrary to the ARI and CLI, such other indexes are based on a syllable count and therefore arguably only work for English and not Swedish.
We compute a further compound lexical diversity index, which should range from 1 to a 100 (with the standard deviation being around 10, and its average value being around 50) - it is 80 in the present case. The compound lexical diversity index consists of the following indexes, averaged out (and also provided in the table above):
- the Measure of Textual Lexical Diversity (MTLD) index - a measure which is based on computing the TTR for increasingly larger parts of the text until the TTR drops below a certain threshold point (around 0.7 in our case) - in which case, the TTR is reset, and the overall counter is increased; the counter is at the end divided by the number of words in text; as a result, the MTLD does not significantly vary by text length;
- the Yule's I index (based on Yule's K characteristic inverted) - an index based on the work of the statistician G.U. Yule, who published his index of Frequency Vocabulary in his paper "The statistical study of literary vocabulary"; Yule's I takes into account the number of words in the text, and a compound summed measure of word frequency;
- the Hypergeometric Distribution D (HD-D) index (based on vocd) - an index which assesses the contribution of each word to the diversity of the text; to calculate such contributions, a hypergeometric distribution is used to compute probabilities of each word appearing in word samples extracted from the text; then such distributions are divided by sample sizes and added up;
Our overall measure of grammatical diversity is based on a combination of the compound lexical diversity index (which includes the MTLD, Yule's I and HD-D indexes), the ARI and CLI, all normalized and given certain weight. The score should normally range from 1 to 100. In this case, the score is 76.
Other Information about Sophie Hagman och hennes samtida by Carl Forsstrand
We provide you a sample of the text below, however, the full text of the Sophie Hagman och hennes samtida is also available free of charge on our website.
Sample of text:
Så var nog också förhållandet med det förgyllda pelarbordet med dess hvita marmorskifva, den stora väggspegeln, ljuskronan och bordstudsaren under sin glaskupa, och till gemakets säkerligen behagliga prägel bidrogo utan tvifvel äfven gardinerna af »brocherad nettelduk med förgyllda brickor». I den rymliga salen funnos två matbord, ett spelbord af mahogny med fällskifva, ett litet tebord af mahogny, sex korgflätade stolar, en målad skänk, en salslykta och två rullgardiner, men gula förmaket var tydligen ett helt litet rum, ett kabinett, hufvudsakligen afsedt för blott smärre samkväm och tedrickning, ty enligt bouppteckningen utgjordes möblemanget här hufvudsakligen af ett tebord af mahogny, ett spelbord, ett sybord o. s. v. 62I bostaden vid Kina var möbleringen utan tvifvel enklare, och det hela hade väl öfver sig den ganska nspråkslösa men ovanligt trefliga stämning, som följde ed den gustavianska tidens hvitmålade eller pärlfärgade ch med blommigt kattun klädda möbler, sängar med mhängen, nettelduksgardiner med bollfransar o. s. v.; en äfven här hade blå förmaket en prydligare och yrbarare utstyrsel, afsedt som det utan tvifvel var till mottagnings- och sällskapsrum, medan de öfriga gemaken ch rummen mest voro ordnade som sofrum. Nämnda förmak var sålunda möbleradt med soffa med tagelstoppning och röd merinobeklädnad och sex ryggdynor, klädda med kattun, sex stolar och två länstolar, ett mahognybord med skifva, ett rundt mahognybord och en stor förgylld spegel, och bland prydnadssaker märkas en byst af gips på piedestal af trä, potpourri-kruka af ostindiskt porslin o. s. v. Förteckningen å husgerådet erbjuder mindre intresse, fastän t. ex. de här omnämnda serviserna af Rörstrandsporslin och de slipade dricksglasen, likörglasen med förgyllda stjärnor, tekannorna och skålarna m. m. af svart engelskt porslin o. s. v., nog i våra dagar skulle uppskattas som värdefulla rariteter. Silfver och koppar fanns på gammalt hedervärdt sätt ej i obetydlig mängd, såsom ej mindre än 756 Vs lod af det förra af 115 1/2 marker af det senare. Bland silfverpjäserna må nämnas 2 sockerskrin, kaffekanna, 8 hela kuvert, förgyllda teskedar, ett handfat m. m. Af större intresse äro emellertid uppgifterna om den bortgångnas så att säga mer personliga kvarlåtenskap: smycken och nipper samt garderoben. Man kunde ha väntat att en så elegant och uppmärksammad dam bjsom Sophie Hagman skulle ha efterlämnat ett mycket rikligt försedt juvelskrin, men så var näppeligen fallet, vare sig hon möjligen vid mognare ålder af ekonomiska eller andra skäl hade afyttrat en del smycken, som hon till äfventyrs ägt, eller anspråkslös och grannlaga som hon var aldrig hade lagt an på att förvärfva sådana i sådan myckenhet som t. ex. hennes samtida mamsell Slottsberg eller andra damer tillhörande den verkliga gustavianska demimonden. Under rubriken »juveler, guld och nipper» upptager sålunda förteckningen endast följande saker, af hvilka några dock voro värdefulla nog: ett par armband med 652 äkta pärlor och juvelslås (454 rdr. 32 sk. b.), ett par briljantörhängen (166 rdr. 32 sk. b.), två briljantringar, två ringar med infattade rosenstenar och kulörta stenar, fem ringar, vägande 3 Vs dukater, och ett guldhjärta med glasinfattning. Främst i den länga förteckningen på gångkläderna upptages en grå levantinspelis med bräm af islands-björnskinn, och sedan följa en svart sådan med gråverk, en hufva kantad med sammet, en kapott af svart siden med stoppning, en d:o af grönt d:o med d:o, två ging-hamsrockar med sidenfoder, en hvit cambricsrock med garnering, klädningar af svart och grått siden, mörkblått ylle, rutigt gingham, broderad cambric och nettel-duk, en stubb af sticktyg, flera schalar, en mängd s. k. onämnbara plagg, en krage af gråverk, en hvit hatt med kulörta plymer, en florshatt med blommor, två svarta sammetshattar med plymer, ett par toque"r af svart sammet, en »Canton med tre hvita plymer och åtskilliga bouquetter», en tyll-coiffure med blommor, tyllmössor, »galoscherade» kängor, skor af grönt siden 64o. s. v. Vid några af dessa persedlar finnes angifvet, att de voro »gamla», hvadan de antagligen utgjorde rester från ägarinnans blomstringstid, men äfven om garderoben kanske också i öfrigt ej kunnat undgå att nås af tidens tand, får man dock det hufvudintrycket, att Sophie Hagman äfven på gamla dagar var en mycket elegant dam och att det ännu vid midten af 1820-talet måtte ha hvilat en säregen rokoko-prägel öfver hennes toaletter af frasande siden, broderad nettelduk och garnerad cambric. Sedan begrafningskostnaderna, utskylder och en del andra utgifter samt boets skulder, hvilka hufvudsakligen utgjordes af räkningar hos diverse handlande och handtverkare afdragits, bestod behållningen såsom här ofvan nämnts af 1,227 r^r- 3 sk- 3 r. banko, hvilka tillföllo den aflidnas systerbarn enligt efterföljande om gifvarinnans goda hjärta och vackra lifsåskådning men äfven rätt klena rättstafning vittnande testamente: »Min sista vilja är att mina 3:ne systerbarn Petter Bjurström, Sophie Bjurström samt Gustafva (Augusta?) Bjurström skal obehindrat ärfva min qvarlåttenhett. Efter min död, sedan min Begrafn. är gord, som skal blifva som följer, min kröp skal liga En dag i sängen kvar sedan den Högste Guden behagat kalla mig Hedan, kroppen skal läges uti Ett Lakan och ingen annan svepning, kista skal vara ganska Simpel utan Decoratjoner; Begrafningen får ej ske för En 4—5 Dyng efter min död, Kjörkans folk skal Bära Likett, ingen bjudning af andra personer, inga klockor uttan när tacksägelse sker till Gud som behagat kalla mig hedan, den qvarlåtenhet som kan vara Efter mig skal sälja(s) och Summan däraf skal placeras på något Sophie Hagman. ...
Top most frequently used words in Sophie Hagman och hennes samtida by Carl Forsstrand*
| Position | Word | Repetitions | Part of all words |
|---|---|---|---|
| Position | Word | Repetitions | Part of all words |
| 1 | och | 1,801 | 3.38% |
| 2 | af | 978 | 1.84% |
| 3 | att | 965 | 1.81% |
| 4 | med | 735 | 1.38% |
| 5 | som | 720 | 1.35% |
| 6 | den | 701 | 1.32% |
| 7 | en | 669 | 1.26% |
| 8 | till | 478 | 0.9% |
| 9 | för | 462 | 0.87% |
| 10 | det | 410 | 0.77% |
| 11 | på | 410 | 0.77% |
| 12 | hon | 379 | 0.71% |
| 13 | var | 373 | 0.7% |
| 14 | de | 342 | 0.64% |
| 15 | vid | 329 | 0.62% |
| 16 | om | 327 | 0.61% |
| 17 | han | 306 | 0.57% |
| 18 | ett | 285 | 0.53% |
| 19 | sid | 285 | 0.53% |
| 20 | sig | 279 | 0.52% |
| 21 | ej | 268 | 0.5% |
| 22 | hade | 244 | 0.46% |
| 23 | sin | 240 | 0.45% |
| 24 | men | 228 | 0.43% |
| 25 | så | 217 | 0.41% |
| 26 | är | 195 | 0.37% |
| 27 | hennes | 194 | 0.36% |
| 28 | hans | 185 | 0.35% |
| 29 | eller | 175 | 0.33% |
| 30 | år | 162 | 0.3% |
| 31 | man | 161 | 0.3% |
| 32 | henne | 157 | 0.29% |
| 33 | Sophie | 154 | 0.29% |
| 34 | Hagman | 145 | 0.27% |
| 35 | mamsell | 143 | 0.27% |
| 36 | har | 142 | 0.27% |
| 37 | äfven | 141 | 0.26% |
| 38 | ha | 141 | 0.26% |
| 39 | under | 134 | 0.25% |
| 40 | Gustaf | 129 | 0.24% |
| 41 | hertigen | 125 | 0.23% |
| 42 | från | 121 | 0.23% |
| 43 | skulle | 116 | 0.22% |
| 44 | jag | 114 | 0.21% |
| 45 | denna | 112 | 0.21% |
| 46 | nämligen | 111 | 0.21% |
| 47 | honom | 111 | 0.21% |
| 48 | då | 110 | 0.21% |
| 49 | sina | 109 | 0.2% |
| 50 | än | 108 | 0.2% |
| 51 | icke | 101 | 0.19% |
| 52 | hos | 100 | 0.19% |
| 53 | efter | 99 | 0.19% |
| 54 | detta | 98 | 0.18% |
| 55 | sitt | 95 | 0.18% |
| 56 | Slottsberg | 93 | 0.17% |
| 57 | mycket | 93 | 0.17% |
| 58 | nu | 93 | 0.17% |
| 59 | några | 91 | 0.17% |
| 60 | hertig | 90 | 0.17% |
| 61 | andra | 89 | 0.17% |
| 62 | vara | 88 | 0.17% |
| 63 | väl | 88 | 0.17% |
| 64 | Fredrik | 87 | 0.16% |
| 65 | där | 84 | 0.16% |
| 66 | blef | 83 | 0.16% |
| 67 | bland | 83 | 0.16% |
| 68 | såsom | 83 | 0.16% |
| 69 | hvilken | 82 | 0.15% |
| 70 | Carl | 82 | 0.15% |
| 71 | utan | 80 | 0.15% |
| 72 | von | 78 | 0.15% |
| 73 | här | 75 | 0.14% |
| 74 | första | 73 | 0.14% |
| 75 | kan | 72 | 0.14% |
| 76 | varit | 72 | 0.14% |
| 77 | samt | 71 | 0.13% |
| 78 | Stockholm | 69 | 0.13% |
| 79 | Eckerman | 69 | 0.13% |
| 80 | någon | 67 | 0.13% |
| 81 | allt | 66 | 0.12% |
| 82 | öfver | 66 | 0.12% |
| 83 | ganska | 66 | 0.12% |
| 84 | redan | 65 | 0.12% |
| 85 | ty | 65 | 0.12% |
| 86 | alla | 64 | 0.12% |
| 87 | voro | 63 | 0.12% |
| 88 | hertigens | 62 | 0.12% |
| 89 | mer | 62 | 0.12% |
| 90 | sedan | 61 | 0.11% |
| 91 | frih | 59 | 0.11% |
| 92 | hur | 59 | 0.11% |
| 93 | dock | 58 | 0.11% |
| 94 | dem | 57 | 0.11% |
| 95 | följande | 57 | 0.11% |
| 96 | enligt | 56 | 0.11% |
| 97 | teatern | 56 | 0.11% |
| 98 | grefve | 56 | 0.11% |
| 99 | konungen | 56 | 0.11% |
| 100 | få | 56 | 0.11% |
| 101 | sålunda | 55 | 0.1% |
| 102 | Hagmans | 54 | 0.1% |
| 103 | nog | 54 | 0.1% |
| 104 | två | 53 | 0.1% |
| 105 | något | 53 | 0.1% |
| 106 | annat | 53 | 0.1% |
| 107 | emellertid | 53 | 0.1% |
| 108 | Adolf | 52 | 0.1% |
| 109 | ännu | 52 | 0.1% |
| 110 | Charlotta | 52 | 0.1% |
| 111 | må | 50 | 0.09% |
| 112 | Johan | 49 | 0.09% |
| 113 | bref | 48 | 0.09% |
| 114 | talet | 48 | 0.09% |
| 115 | fru | 47 | 0.09% |
| 116 | rdr | 47 | 0.09% |
| 117 | mindre | 47 | 0.09% |
| 118 | dessa | 46 | 0.09% |
| 119 | mig | 45 | 0.08% |
| 120 | skall | 45 | 0.08% |
| 121 | blott | 45 | 0.08% |
| 122 | uti | 45 | 0.08% |
| 123 | också | 45 | 0.08% |
| 124 | hvilka | 44 | 0.08% |
| 125 | åt | 43 | 0.08% |
| 126 | vackra | 43 | 0.08% |
| 127 | genom | 43 | 0.08% |
| 128 | samma | 41 | 0.08% |
| 129 | anledning | 41 | 0.08% |
| 130 | gjorde | 41 | 0.08% |
| 131 | flera | 41 | 0.08% |
| 132 | konungens | 40 | 0.08% |
| 133 | Fersen | 40 | 0.08% |
| 134 | kunde | 40 | 0.08% |
| 135 | Sophia | 40 | 0.08% |
| 136 | hvars | 39 | 0.07% |
| 137 | tid | 39 | 0.07% |
| 138 | själf | 39 | 0.07% |
| 139 | unga | 38 | 0.07% |
| 140 | Badin | 38 | 0.07% |
| 141 | gustavianska | 38 | 0.07% |
| 142 | huset | 37 | 0.07% |
| 143 | franska | 37 | 0.07% |
| 144 | hvad | 37 | 0.07% |
| 145 | III | 37 | 0.07% |
| 146 | rum | 37 | 0.07% |
| 147 | många | 37 | 0.07% |
| 148 | hela | 36 | 0.07% |
| 149 | fick | 36 | 0.07% |
| 150 | tiden | 36 | 0.07% |
| 151 | blifvit | 36 | 0.07% |
| 152 | mera | 36 | 0.07% |
| 153 | 1790 | 35 | 0.07% |
| 154 | par | 35 | 0.07% |
| 155 | sätt | 35 | 0.07% |
| 156 | äro | 34 | 0.06% |
| 157 | bodde | 34 | 0.06% |
| 158 | göra | 34 | 0.06% |
| 159 | Fredrika | 34 | 0.06% |
| 160 | samband | 33 | 0.06% |
| 161 | namn | 33 | 0.06% |
| 162 | mot | 33 | 0.06% |
| 163 | åter | 33 | 0.06% |
| 164 | min | 32 | 0.06% |
| 165 | intresse | 32 | 0.06% |
| 166 | hafva | 32 | 0.06% |
| 167 | ur | 32 | 0.06% |
| 168 | skrifver | 32 | 0.06% |
| 169 | ofta | 32 | 0.06% |
| 170 | Charlotte | 32 | 0.06% |
| 171 | Crusenstolpe | 32 | 0.06% |
| 172 | antagligen | 31 | 0.06% |
| 173 | hvilket | 31 | 0.06% |
| 174 | torde | 31 | 0.06% |
| 175 | snart | 31 | 0.06% |
| 176 | 1780 | 30 | 0.06% |
| 177 | öfrigt | 30 | 0.06% |
| 178 | förut | 30 | 0.06% |
This list excludes punctuation or single-letter words, also some different-case repeats of the same words.
If you think the text would be accessible to you, you can read it on our site (click on the cover to access):

Other resources and languages
If you like this analysis, you should have a look at out our lists of Swedish short stories and Swedish books.
If you like literature as a means to learn languages - please take a look at our project Interlinear Books. We even have a Swedish Interlinear book available for purchase.