Ödemarkens hemlighet by Ernest Favenc : Difficulty Assessment for Swedish Learners
How difficult is Ödemarkens hemlighet for Swedish learners? We have performed multiple tests on its full text (freely available here) of approximately 52,533, crunched all the numbers for you and present the results below.
Read the Full Text Now for Free!
Difficulty Assessment Summary
We have estimated Ödemarkens hemlighet to have a difficulty score of 56. Here're its scores:
| Measure | Score | |
|---|---|---|
| easy difficult | (1 - 100) | |
| Overall Difficulty | 56 | |
| Vocabulary Difficulty | 55 | |
| Grammatical Difficulty | 57 |
Vocabulary Difficulty: Breakdown
Vocabulary difficulty: 55%
This score has been calculated based on frequency vocabulary (the top most frequently used words in Swedish). It combines various measures of Ödemarkens hemlighet's text analyzed in terms of frequency vocabulary: a plain vocabulary score, frequency-weighted vocabulary score, banded frequency vocabulary scores based on vocabulary of the text falling in the top 1,000 or 2,000 most frequent words, etc. Here's a further breakdown of how often the top most frequently used words in Swedish appear in the full text of Ödemarkens hemlighet:

We have also calculated the following approximate data on the vocabulary in Ödemarkens hemlighet:
| Measure | Score |
|---|---|
| Measure | Score |
| Number of words | 52,533 |
| Number of unique words | 8,065 |
| Number of recognized words for names/places/other entities | 2,070 |
| Number of very rare non-entity words | 1,011 |
| Number of sentences | 8,058 |
| Average number of words/sentence | 7 |
There is some research suggesting that that you need to know about 98% of a text's vocabulary in order to be able to infer the meaning of unknown words when reading. If true, this means that you would need to know around 7,903 words (where all the forms of the word are still counted as unique words) in Swedish to be able to read Ödemarkens hemlighet without a dictionary and fully understand it.
Grammatical Difficulty: Breakdown
Grammatical difficulty: 57%
Here is the further grammatical comparison on this text. You can find an explanation of all these scores below.
| Measure | Score |
|---|---|
| Measure | Score |
| Automated Readability Index | 4 |
| Coleman-Liau Index | 8 |
| Type/Token Ratio (TTR) | 0.153523 |
| Root type/Token Ratio (RTTR) | 0.0000029224 |
| Corrected type/Token Ratio (CTTR) | 0.0000014612 |
| MTLD Index | 78 |
| HDD Index | 68 |
| Yule's I Index | 81 |
| Lexical Diversity Index (MTLD + HD-D + Yule's I) | 76 |
The type-token ratio (TTR) of Ödemarkens hemlighet is 0.153523. The TTR is the most basic measure of lexical diversity. To calculate it, we divide the number of unique words by the number of words in the text. For example, for this text, the number of unique words is 8,065, while the number of words is 52,533, so the TTR is 8,065 / 52,533 = 0.153523. However, the TTR is a very crude measure, as it is extremely dependent on text length. The longer the text, the lower the TTR is usually going to be, since common words tend to often repeat. Especially since the number of words in this text is more than 1,000, the TTR is not likely to give an accurate measure.
The root type-token ratio (RTTR) and corrected type-token ratio (CTTR) are measures which were suggested by researchers to partially address the problem of TTR's variance on text length. In the RTTR, the number of unique words is divided by a square of the number of words (therefore, 8,065 / (52,533 * 52,533) = 0.0000029224), while in CTTR, it is divided by a square of the number of words, multiplied twice 8,065 / 2 * (52,533 * 52,533) = 0.0000014612). However, these measures are not as easily readable, and also there is a growing body of research asserting that CTTR and RTTR do not effectively address the problems of text length. Therefore, while we do provide the full text's TTR, RTTR and CTTR on this page, these fiqures do not form part of our final calculations.
The Automated Readability Index (ARI) is one readability measure that has been developed by researchers over the years. The formula for calculating the ARI is as follows: 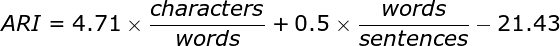
The ARI should compute a reading level approximately corresponding to the reader's grade level (assuming the reader undertakes formal education). Thus, for example, a value of 1 is kindergarten level, while a value of 12 or 13 is the last year of school, and 14 is a sophomore at college. The current ARI of this text is 4, making it understandable for 4-grade students at their expected level of education.
The Coleman Liau Index (CLI) is a similar index designed by Meri Coleman and T. L. Liau, and it is supposed to compute the grade level of the reader (thus, for example, sophomore level material would be around grade 14, or year 14 of formal education, while kindergarten / primary school level material would be close to grade 1 in the CLI). The CLI is usually slightly higher than the ARI. The CLI is computed with this formula:
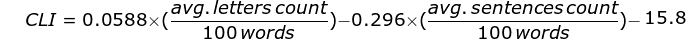
It is notable that other indexes exist, such as the Flesch-Kincaid Reading Ease, Gunning-Fog Score, and others, but we have chosen not to include them, since, contrary to the ARI and CLI, such other indexes are based on a syllable count and therefore arguably only work for English and not Swedish.
We compute a further compound lexical diversity index, which should range from 1 to a 100 (with the standard deviation being around 10, and its average value being around 50) - it is 76 in the present case. The compound lexical diversity index consists of the following indexes, averaged out (and also provided in the table above):
- the Measure of Textual Lexical Diversity (MTLD) index - a measure which is based on computing the TTR for increasingly larger parts of the text until the TTR drops below a certain threshold point (around 0.7 in our case) - in which case, the TTR is reset, and the overall counter is increased; the counter is at the end divided by the number of words in text; as a result, the MTLD does not significantly vary by text length;
- the Yule's I index (based on Yule's K characteristic inverted) - an index based on the work of the statistician G.U. Yule, who published his index of Frequency Vocabulary in his paper "The statistical study of literary vocabulary"; Yule's I takes into account the number of words in the text, and a compound summed measure of word frequency;
- the Hypergeometric Distribution D (HD-D) index (based on vocd) - an index which assesses the contribution of each word to the diversity of the text; to calculate such contributions, a hypergeometric distribution is used to compute probabilities of each word appearing in word samples extracted from the text; then such distributions are divided by sample sizes and added up;
Our overall measure of grammatical diversity is based on a combination of the compound lexical diversity index (which includes the MTLD, Yule's I and HD-D indexes), the ARI and CLI, all normalized and given certain weight. The score should normally range from 1 to 100. In this case, the score is 57.
Other Information about Ödemarkens hemlighet by Ernest Favenc
We provide you a sample of the text below, however, the full text of the Ödemarkens hemlighet is also available free of charge on our website.
Sample of text:
»Tror ni, att alla dessa vackra träd komma att dö, om vattnet torkar ut?» frågade Charlie. »Säkerligen. Men då deras rötter gå djupt ned, torde de stå sig ännu åtskiliga år.» Följande morgon visade Columbus dem på det spår, som de en gång förut följt, och snart hade de lämnat sumptrakten bakom sig. Landskapet var utomordentligt monotont, och de kunde icke upptäcka något avbrott i skogens enformighet förrän fram på eftermiddagen, då de helt oväntat påträffade en ravin, samtidigt med att landet började visa sig bördigare och rikligare försett med gräsväxt. Läger uppslogs ...
Top most frequently used words in Ödemarkens hemlighet by Ernest Favenc*
| Position | Word | Repetitions | Part of all words |
|---|---|---|---|
| Position | Word | Repetitions | Part of all words |
| 1 | att | 1,409 | 2.68% |
| 2 | och | 1,399 | 2.66% |
| 3 | en | 890 | 1.69% |
| 4 | de | 784 | 1.49% |
| 5 | som | 745 | 1.42% |
| 6 | av | 723 | 1.38% |
| 7 | på | 654 | 1.24% |
| 8 | det | 625 | 1.19% |
| 9 | med | 569 | 1.08% |
| 10 | till | 540 | 1.03% |
| 11 | sig | 536 | 1.02% |
| 12 | den | 531 | 1.01% |
| 13 | för | 513 | 0.98% |
| 14 | han | 423 | 0.81% |
| 15 | jag | 380 | 0.72% |
| 16 | vi | 375 | 0.71% |
| 17 | var | 372 | 0.71% |
| 18 | ett | 371 | 0.71% |
| 19 | om | 332 | 0.63% |
| 20 | Brown | 286 | 0.54% |
| 21 | Morton | 284 | 0.54% |
| 22 | hade | 259 | 0.49% |
| 23 | så | 234 | 0.45% |
| 24 | icke | 229 | 0.44% |
| 25 | där | 224 | 0.43% |
| 26 | men | 213 | 0.41% |
| 27 | nu | 212 | 0.4% |
| 28 | vid | 208 | 0.4% |
| 29 | ha | 207 | 0.39% |
| 30 | dem | 203 | 0.39% |
| 31 | något | 193 | 0.37% |
| 32 | då | 189 | 0.36% |
| 33 | är | 186 | 0.35% |
| 34 | efter | 186 | 0.35% |
| 35 | från | 180 | 0.34% |
| 36 | Charlie | 166 | 0.32% |
| 37 | mig | 164 | 0.31% |
| 38 | oss | 161 | 0.31% |
| 39 | inte | 156 | 0.3% |
| 40 | upp | 151 | 0.29% |
| 41 | här | 145 | 0.28% |
| 42 | skulle | 144 | 0.27% |
| 43 | Billy | 143 | 0.27% |
| 44 | sin | 139 | 0.26% |
| 45 | under | 138 | 0.26% |
| 46 | honom | 134 | 0.26% |
| 47 | vara | 129 | 0.25% |
| 48 | man | 129 | 0.25% |
| 49 | ut | 126 | 0.24% |
| 50 | kunde | 122 | 0.23% |
| 51 | några | 119 | 0.23% |
| 52 | har | 118 | 0.22% |
| 53 | fram | 115 | 0.22% |
| 54 | ni | 115 | 0.22% |
| 55 | någon | 110 | 0.21% |
| 56 | genom | 109 | 0.21% |
| 57 | åt | 104 | 0.2% |
| 58 | över | 103 | 0.2% |
| 59 | än | 100 | 0.19% |
| 60 | voro | 99 | 0.19% |
| 61 | Columbus | 97 | 0.18% |
| 62 | eller | 96 | 0.18% |
| 63 | deras | 96 | 0.18% |
| 64 | ned | 96 | 0.18% |
| 65 | vad | 94 | 0.18% |
| 66 | hans | 92 | 0.18% |
| 67 | komma | 91 | 0.17% |
| 68 | snart | 91 | 0.17% |
| 69 | svarta | 90 | 0.17% |
| 70 | kunna | 89 | 0.17% |
| 71 | utan | 88 | 0.17% |
| 72 | mot | 87 | 0.17% |
| 73 | måste | 87 | 0.17% |
| 74 | göra | 86 | 0.16% |
| 75 | andra | 83 | 0.16% |
| 76 | denna | 83 | 0.16% |
| 77 | allt | 79 | 0.15% |
| 78 | nog | 78 | 0.15% |
| 79 | vatten | 76 | 0.14% |
| 80 | sina | 76 | 0.14% |
| 81 | ännu | 76 | 0.14% |
| 82 | samma | 73 | 0.14% |
| 83 | alla | 72 | 0.14% |
| 84 | få | 72 | 0.14% |
| 85 | emellertid | 72 | 0.14% |
| 86 | medan | 70 | 0.13% |
| 87 | endast | 69 | 0.13% |
| 88 | varit | 66 | 0.13% |
| 89 | mycket | 65 | 0.12% |
| 90 | tycktes | 65 | 0.12% |
| 91 | detta | 64 | 0.12% |
| 92 | båda | 64 | 0.12% |
| 93 | sjön | 63 | 0.12% |
| 94 | tillbaka | 63 | 0.12% |
| 95 | därpå | 63 | 0.12% |
| 96 | två | 62 | 0.12% |
| 97 | lägret | 62 | 0.12% |
| 98 | sade | 62 | 0.12% |
| 99 | kan | 59 | 0.11% |
| 100 | omkring | 59 | 0.11% |
| 101 | se | 59 | 0.11% |
| 102 | platsen | 58 | 0.11% |
| 103 | bland | 58 | 0.11% |
| 104 | torde | 57 | 0.11% |
| 105 | ty | 56 | 0.11% |
| 106 | följa | 56 | 0.11% |
| 107 | samt | 56 | 0.11% |
| 108 | riktning | 55 | 0.1% |
| 109 | började | 55 | 0.1% |
| 110 | kommit | 54 | 0.1% |
| 111 | gamla | 54 | 0.1% |
| 112 | dessa | 52 | 0.1% |
| 113 | syntes | 52 | 0.1% |
| 114 | väg | 51 | 0.1% |
| 115 | sitt | 51 | 0.1% |
| 116 | spår | 51 | 0.1% |
| 117 | när | 51 | 0.1% |
| 118 | visade | 51 | 0.1% |
| 119 | äro | 51 | 0.1% |
| 120 | tid | 50 | 0.1% |
| 121 | blev | 49 | 0.09% |
| 122 | sedan | 49 | 0.09% |
| 123 | långt | 48 | 0.09% |
| 124 | hava | 48 | 0.09% |
| 125 | min | 47 | 0.09% |
| 126 | in | 47 | 0.09% |
| 127 | gott | 47 | 0.09% |
| 128 | hur | 46 | 0.09% |
| 129 | kom | 46 | 0.09% |
| 130 | hela | 46 | 0.09% |
| 131 | gjorde | 46 | 0.09% |
| 132 | våra | 46 | 0.09% |
| 133 | även | 46 | 0.09% |
| 134 | Warlattas | 45 | 0.09% |
| 135 | vägen | 45 | 0.09% |
| 136 | fanns | 44 | 0.08% |
| 137 | vita | 44 | 0.08% |
| 138 | gick | 44 | 0.08% |
| 139 | Lee | 43 | 0.08% |
| 140 | grottan | 43 | 0.08% |
| 141 | blivit | 43 | 0.08% |
| 142 | dess | 43 | 0.08% |
| 143 | just | 42 | 0.08% |
| 144 | tre | 41 | 0.08% |
| 145 | såg | 40 | 0.08% |
| 146 | följde | 40 | 0.08% |
| 147 | helt | 40 | 0.08% |
| 148 | natten | 40 | 0.08% |
| 149 | låg | 40 | 0.08% |
| 150 | tiden | 40 | 0.08% |
| 151 | gång | 40 | 0.08% |
| 152 | ravinen | 40 | 0.08% |
| 153 | innan | 40 | 0.08% |
| 154 | Stuart | 39 | 0.07% |
| 155 | taga | 39 | 0.07% |
| 156 | borde | 39 | 0.07% |
| 157 | bort | 39 | 0.07% |
| 158 | hos | 39 | 0.07% |
| 159 | litet | 39 | 0.07% |
| 160 | morgon | 38 | 0.07% |
| 161 | alldeles | 38 | 0.07% |
| 162 | mil | 38 | 0.07% |
| 163 | vidare | 38 | 0.07% |
| 164 | åter | 38 | 0.07% |
| 165 | ur | 38 | 0.07% |
| 166 | hördes | 38 | 0.07% |
| 167 | infödingarna | 38 | 0.07% |
| 168 | gjort | 37 | 0.07% |
| 169 | finna | 37 | 0.07% |
| 170 | förut | 37 | 0.07% |
| 171 | väl | 37 | 0.07% |
| 172 | frågade | 37 | 0.07% |
| 173 | annat | 37 | 0.07% |
| 174 | dagen | 36 | 0.07% |
| 175 | gå | 36 | 0.07% |
| 176 | sällskapet | 36 | 0.07% |
| 177 | stod | 36 | 0.07% |
| 178 | vilken | 36 | 0.07% |
| 179 | mitt | 35 | 0.07% |
| 180 | fortsatte | 35 | 0.07% |
| 181 | första | 35 | 0.07% |
| 182 | vilka | 35 | 0.07% |
| 183 | tog | 35 | 0.07% |
| 184 | berget | 34 | 0.06% |
This list excludes punctuation or single-letter words, also some different-case repeats of the same words.
If you think the text would be accessible to you, you can read it on our site (click on the cover to access):

Other resources and languages
If you like this analysis, you should have a look at out our lists of Swedish short stories and Swedish books.
If you like literature as a means to learn languages - please take a look at our project Interlinear Books. We even have a Swedish Interlinear book available for purchase.