Случай из практики (Sluchaj iz praktiki) by Антон Чехов (Anton Chehov): Difficulty Assessment for Russian Learners
How difficult is Случай из практики (Sluchaj iz praktiki) for Russian learners? We have performed multiple tests on its full text (freely available here) of approximately 3,260, crunched all the numbers for you and present the results below.
Read the Full Text Now for Free!
Difficulty Assessment Summary
We have estimated Случай из практики to have a difficulty score of 69. Here're its scores:
| Measure | Score | |
|---|---|---|
| easy difficult | (1 - 100) | |
| Overall Difficulty | 69 | |
| Vocabulary Difficulty | 64 | |
| Grammatical Difficulty | 73 |
Vocabulary Difficulty: Breakdown
Vocabulary difficulty: 64%
This score has been calculated based on frequency vocabulary (the top most frequently used words in Russian). It combines various measures of Случай из практики's text analyzed in terms of frequency vocabulary: a plain vocabulary score, frequency-weighted vocabulary score, banded frequency vocabulary scores based on vocabulary of the text falling in the top 1,000 or 2,000 most frequent words, etc. Here's a further breakdown of how often the top most frequently used words in Russian appear in the full text of Случай из практики:

We have also calculated the following approximate data on the vocabulary in Случай из практики:
| Measure | Score |
|---|---|
| Measure | Score |
| Number of words | 3,260 |
| Number of unique words | 1,582 |
| Number of recognized words for names/places/other entities | 145 |
| Number of very rare non-entity words | 25 |
| Number of sentences | 211 |
| Average number of words/sentence | 15 |
There is some research suggesting that that you need to know about 98% of a text's vocabulary in order to be able to infer the meaning of unknown words when reading. If true, this means that you would need to know around 1,550 words (where all the forms of the word are still counted as unique words) in Russian to be able to read Случай из практики without a dictionary and fully understand it.
Grammatical Difficulty: Breakdown
Grammatical difficulty: 73%
Here is the further grammatical comparison on this text. You can find an explanation of all these scores below.
| Measure | Score |
|---|---|
| Measure | Score |
| Automated Readability Index | 10 |
| Coleman-Liau Index | 12 |
| Type/Token Ratio (TTR) | 0.485276 |
| Root type/Token Ratio (RTTR) | 0.000148858 |
| Corrected type/Token Ratio (CTTR) | 0.0000744288 |
| MTLD Index | 106 |
| HDD Index | 71 |
| Yule's I Index | 79 |
| Lexical Diversity Index (MTLD + HD-D + Yule's I) | 85 |
The type-token ratio (TTR) of Случай из практики is 0.485276. The TTR is the most basic measure of lexical diversity. To calculate it, we divide the number of unique words by the number of words in the text. For example, for this text, the number of unique words is 1,582, while the number of words is 3,260, so the TTR is 1,582 / 3,260 = 0.485276. However, the TTR is a very crude measure, as it is extremely dependent on text length. The longer the text, the lower the TTR is usually going to be, since common words tend to often repeat. Especially since the number of words in this text is more than 1,000, the TTR is not likely to give an accurate measure.
The root type-token ratio (RTTR) and corrected type-token ratio (CTTR) are measures which were suggested by researchers to partially address the problem of TTR's variance on text length. In the RTTR, the number of unique words is divided by a square of the number of words (therefore, 1,582 / (3,260 * 3,260) = 0.000148858), while in CTTR, it is divided by a square of the number of words, multiplied twice 1,582 / 2 * (3,260 * 3,260) = 0.0000744288). However, these measures are not as easily readable, and also there is a growing body of research asserting that CTTR and RTTR do not effectively address the problems of text length. Therefore, while we do provide the full text's TTR, RTTR and CTTR on this page, these fiqures do not form part of our final calculations.
The Automated Readability Index (ARI) is one readability measure that has been developed by researchers over the years. The formula for calculating the ARI is as follows: 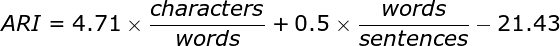
The ARI should compute a reading level approximately corresponding to the reader's grade level (assuming the reader undertakes formal education). Thus, for example, a value of 1 is kindergarten level, while a value of 12 or 13 is the last year of school, and 14 is a sophomore at college. The current ARI of this text is 10, making it understandable for 10-grade students at their expected level of education.
The Coleman Liau Index (CLI) is a similar index designed by Meri Coleman and T. L. Liau, and it is supposed to compute the grade level of the reader (thus, for example, sophomore level material would be around grade 14, or year 14 of formal education, while kindergarten / primary school level material would be close to grade 1 in the CLI). The CLI is usually slightly higher than the ARI. The CLI is computed with this formula:
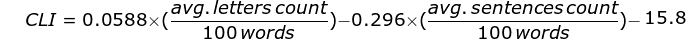
It is notable that other indexes exist, such as the Flesch-Kincaid Reading Ease, Gunning-Fog Score, and others, but we have chosen not to include them, since, contrary to the ARI and CLI, such other indexes are based on a syllable count and therefore arguably only work for English and not Russian.
We compute a further compound lexical diversity index, which should range from 1 to a 100 (with the standard deviation being around 10, and its average value being around 50) - it is 85 in the present case. The compound lexical diversity index consists of the following indexes, averaged out (and also provided in the table above):
- the Measure of Textual Lexical Diversity (MTLD) index - a measure which is based on computing the TTR for increasingly larger parts of the text until the TTR drops below a certain threshold point (around 0.7 in our case) - in which case, the TTR is reset, and the overall counter is increased; the counter is at the end divided by the number of words in text; as a result, the MTLD does not significantly vary by text length;
- the Yule's I index (based on Yule's K characteristic inverted) - an index based on the work of the statistician G.U. Yule, who published his index of Frequency Vocabulary in his paper "The statistical study of literary vocabulary"; Yule's I takes into account the number of words in the text, and a compound summed measure of word frequency;
- the Hypergeometric Distribution D (HD-D) index (based on vocd) - an index which assesses the contribution of each word to the diversity of the text; to calculate such contributions, a hypergeometric distribution is used to compute probabilities of each word appearing in word samples extracted from the text; then such distributions are divided by sample sizes and added up;
Our overall measure of grammatical diversity is based on a combination of the compound lexical diversity index (which includes the MTLD, Yule's I and HD-D indexes), the ARI and CLI, all normalized and given certain weight. The score should normally range from 1 to 100. In this case, the score is 73.
Other Information about Случай из практики by Антон Чехов
We provide you a sample of the text below, however, the full text of the Случай из практики is also available free of charge on our website.
Sample of text:
Так и живем втроем. Летом здесь, а зимой в Москве на Полянке. Я у них уже одиннадцать лет живу. Как своя. К ужину подавали стерлядь, куриные котлеты и компот; вина были дорогие, французские. - Вы, доктор, пожалуйста, без церемонии, - говорила Христина Дмитриевна, кушая, утирая рот кулачком, и видно было, что она жила здесь в свое полное удовольствие. - Пожалуйста, кушайте. После ужина доктора отвели в комнату, где для него была приготовлена постель. Но ему не хотелось спать, было душно, и в комнате пахло краской; он надел пальто и вышел. На дворе было прохладно; уже брезжил рассвет, и в сыром воздухе ясно обозначались все пять корпусов с их длинными трубами, бараки и склады. По случаю праздника не работали, было в окнах темно, и только в одном из корпусов горела еще печь, два окна были багровы, и из трубы вместе с дымом изредка выходил огонь. Далеко за двором кричали лягушки и пел соловей. Глядя на корпуса и на бараки, где спали рабочие, он опять думал о том, о чем думал всегда, когда видел фабрики. Пусть спектакли для рабочих, волшебные фонари, фабричные доктора, разные улучшения, но все же рабочие, которых он встретил сегодня по дороге со станции, ничем не отличаются по виду от тех рабочих, которых он видел давно в детстве, когда еще не было фабричных спектаклей и улучшений. Он, как медик, правильно судивший о хронических страданиях, коренная причина которых была непонятна и неизлечима, и на фабрики смотрел как на недоразумение, причина которого была тоже неясна и неустранима, и все улучшения в жизни фабричных он не считал лишними, но приравнивал их к лечению неизлечимых болезней. "Тут недоразумение, конечно... - думал он, глядя на багровые окна. - Тысячи полторы-две фабричных работают без отдыха, в нездоровой обстановке, делая плохой ситец, живут впроголодь и только изредка в кабаке отрезвляются от этого кошмара; сотня людей надзирает за работой, и вся жизнь этой сотни уходит на записывание штрафов, на брань, несправедливости, и только двое-трое, так называемые хозяева, пользуются выгодами, хотя совсем не работают и презирают плохой ситец. По какие выгоды, как пользуются ими? Ляликова и ее дочь несчастны, на них жалко смотреть, живет в свое удовольствие только одна Христина Дмитриевна, пожилая, глуповатая девица в pince-nez. И выходит так, значит, что работают все эти пять корпусов и на восточных рынках продается плохой ситец для того только, чтобы Христина Дмитриевна могла кушать стерлядь и пить мадеру". Вдруг раздались странные звуки, те самые, которые Королев слышал до ужина. ...
Top most frequently used words in Случай из практики by Антон Чехов*
| Position | Word | Repetitions | Part of all words |
|---|---|---|---|
| Position | Word | Repetitions | Part of all words |
| 1 | не | 64 | 1.96% |
| 2 | на | 55 | 1.69% |
| 3 | что | 39 | 1.2% |
| 4 | он | 30 | 0.92% |
| 5 | она | 26 | 0.8% |
| 6 | все | 26 | 0.8% |
| 7 | как | 24 | 0.74% |
| 8 | то | 23 | 0.71% |
| 9 | Королев | 22 | 0.67% |
| 10 | было | 22 | 0.67% |
| 11 | но | 19 | 0.58% |
| 12 | это | 19 | 0.58% |
| 13 | так | 18 | 0.55% |
| 14 | уже | 15 | 0.46% |
| 15 | по | 13 | 0.4% |
| 16 | только | 13 | 0.4% |
| 17 | для | 13 | 0.4% |
| 18 | же | 13 | 0.4% |
| 19 | ему | 12 | 0.37% |
| 20 | когда | 12 | 0.37% |
| 21 | была | 12 | 0.37% |
| 22 | от | 11 | 0.34% |
| 23 | бы | 11 | 0.34% |
| 24 | ей | 10 | 0.31% |
| 25 | опять | 10 | 0.31% |
| 26 | из | 10 | 0.31% |
| 27 | него | 10 | 0.31% |
| 28 | ее | 10 | 0.31% |
| 29 | ни | 10 | 0.31% |
| 30 | сказал | 9 | 0.28% |
| 31 | корпусов | 9 | 0.28% |
| 32 | его | 9 | 0.28% |
| 33 | сказать | 8 | 0.25% |
| 34 | меня | 8 | 0.25% |
| 35 | дер | 8 | 0.25% |
| 36 | думал | 8 | 0.25% |
| 37 | нее | 8 | 0.25% |
| 38 | за | 8 | 0.25% |
| 39 | были | 8 | 0.25% |
| 40 | фабрики | 8 | 0.25% |
| 41 | вас | 8 | 0.25% |
| 42 | нет | 7 | 0.21% |
| 43 | доктора | 7 | 0.21% |
| 44 | теперь | 7 | 0.21% |
| 45 | быть | 7 | 0.21% |
| 46 | еще | 7 | 0.21% |
| 47 | дочь | 7 | 0.21% |
| 48 | которых | 7 | 0.21% |
| 49 | или | 7 | 0.21% |
| 50 | они | 7 | 0.21% |
| 51 | жизнь | 7 | 0.21% |
| 52 | ночь | 7 | 0.21% |
| 53 | жак | 6 | 0.18% |
| 54 | ничего | 6 | 0.18% |
| 55 | тут | 6 | 0.18% |
| 56 | ли | 6 | 0.18% |
| 57 | себя | 6 | 0.18% |
| 58 | себе | 6 | 0.18% |
| 59 | был | 6 | 0.18% |
| 60 | может | 6 | 0.18% |
| 61 | здесь | 6 | 0.18% |
| 62 | подумал | 5 | 0.15% |
| 63 | мы | 5 | 0.15% |
| 64 | станции | 5 | 0.15% |
| 65 | точно | 5 | 0.15% |
| 66 | мне | 5 | 0.15% |
| 67 | смотрела | 5 | 0.15% |
| 68 | потом | 5 | 0.15% |
| 69 | дрын | 5 | 0.15% |
| 70 | вы | 5 | 0.15% |
| 71 | доме | 5 | 0.15% |
| 72 | чего | 5 | 0.15% |
| 73 | чтобы | 5 | 0.15% |
| 74 | много | 5 | 0.15% |
| 75 | очень | 5 | 0.15% |
| 76 | Дмитриевна | 5 | 0.15% |
| 77 | Христина | 5 | 0.15% |
| 78 | гувернантка | 5 | 0.15% |
| 79 | рабочих | 5 | 0.15% |
| 80 | до | 5 | 0.15% |
| 81 | свое | 5 | 0.15% |
| 82 | руку | 5 | 0.15% |
| 83 | спросил | 5 | 0.15% |
| 84 | рабочие | 5 | 0.15% |
| 85 | звуки | 5 | 0.15% |
| 86 | если | 5 | 0.15% |
| 87 | нас | 5 | 0.15% |
| 88 | чем | 5 | 0.15% |
| 89 | говорить | 4 | 0.12% |
| 90 | них | 4 | 0.12% |
| 91 | эти | 4 | 0.12% |
| 92 | говорила | 4 | 0.12% |
| 93 | видел | 4 | 0.12% |
| 94 | вот | 4 | 0.12% |
| 95 | Ляликова | 4 | 0.12% |
| 96 | глазами | 4 | 0.12% |
| 97 | вдруг | 4 | 0.12% |
| 98 | одного | 4 | 0.12% |
| 99 | тихо | 4 | 0.12% |
| 100 | том | 4 | 0.12% |
| 101 | сам | 4 | 0.12% |
| 102 | этого | 4 | 0.12% |
| 103 | со | 4 | 0.12% |
| 104 | пять | 4 | 0.12% |
| 105 | будто | 4 | 0.12% |
| 106 | лицо | 4 | 0.12% |
| 107 | нибудь | 4 | 0.12% |
| 108 | будет | 4 | 0.12% |
| 109 | ночам | 4 | 0.12% |
| 110 | время | 4 | 0.12% |
| 111 | лица | 4 | 0.12% |
| 112 | кто | 4 | 0.12% |
| 113 | без | 4 | 0.12% |
| 114 | где | 4 | 0.12% |
| 115 | спать | 4 | 0.12% |
| 116 | фабричных | 4 | 0.12% |
| 117 | спали | 4 | 0.12% |
| 118 | кажется | 3 | 0.09% |
| 119 | знал | 3 | 0.09% |
| 120 | Лиза | 3 | 0.09% |
| 121 | через | 3 | 0.09% |
| 122 | разговор | 3 | 0.09% |
| 123 | мать | 3 | 0.09% |
| 124 | какой | 3 | 0.09% |
| 125 | глаза | 3 | 0.09% |
| 126 | работают | 3 | 0.09% |
| 127 | давно | 3 | 0.09% |
| 128 | двора | 3 | 0.09% |
| 129 | казалось | 3 | 0.09% |
| 130 | корпуса | 3 | 0.09% |
| 131 | одинока | 3 | 0.09% |
| 132 | ясно | 3 | 0.09% |
| 133 | вечер | 3 | 0.09% |
| 134 | мало | 3 | 0.09% |
| 135 | одна | 3 | 0.09% |
| 136 | конечно | 3 | 0.09% |
| 137 | ситец | 3 | 0.09% |
| 138 | дьявол | 3 | 0.09% |
| 139 | стояла | 3 | 0.09% |
| 140 | их | 3 | 0.09% |
| 141 | дьявола | 3 | 0.09% |
| 142 | совсем | 3 | 0.09% |
| 143 | спите | 3 | 0.09% |
| 144 | кого | 3 | 0.09% |
| 145 | бараки | 3 | 0.09% |
| 146 | два | 3 | 0.09% |
| 147 | вами | 3 | 0.09% |
| 148 | людей | 3 | 0.09% |
| 149 | окна | 3 | 0.09% |
| 150 | понял | 3 | 0.09% |
| 151 | около | 3 | 0.09% |
| 152 | дворе | 3 | 0.09% |
| 153 | плохой | 3 | 0.09% |
| 154 | pince | 3 | 0.09% |
| 155 | можно | 3 | 0.09% |
| 156 | нужно | 3 | 0.09% |
| 157 | должно | 3 | 0.09% |
| 158 | который | 3 | 0.09% |
| 159 | кругом | 3 | 0.09% |
| 160 | впечатление | 3 | 0.09% |
| 161 | такой | 3 | 0.09% |
| 162 | хотелось | 3 | 0.09% |
| 163 | лет | 3 | 0.09% |
| 164 | солнце | 3 | 0.09% |
| 165 | вышел | 3 | 0.09% |
| 166 | nez | 3 | 0.09% |
| 167 | доктор | 3 | 0.09% |
| 168 | Москве | 3 | 0.09% |
| 169 | поле | 3 | 0.09% |
| 170 | раз | 3 | 0.09% |
| 171 | уйдут | 2 | 0.06% |
| 172 | дело | 2 | 0.06% |
| 173 | пользуются | 2 | 0.06% |
| 174 | ничем | 2 | 0.06% |
| 175 | единственная | 2 | 0.06% |
| 176 | дома | 2 | 0.06% |
| 177 | хуже | 2 | 0.06% |
This list excludes punctuation or single-letter words, also some different-case repeats of the same words.
If you think the text would be accessible to you, you can read it on our site (click on the cover to access):

Other resources and languages
If you like this analysis, you should have a look at out our lists of Russian short stories and Russian books.
If you like literature as a means to learn languages - please take a look at our project Interlinear Books. We even have a Russian Interlinear book available for purchase.