Сиерра-Морена (Sierra-Morena) by Николай Карамзин (Nikolaj Karamzin): Difficulty Assessment for Russian Learners
How difficult is Сиерра-Морена (Sierra-Morena) for Russian learners? We have performed multiple tests on its full text (freely available here) of approximately 1,277, crunched all the numbers for you and present the results below.
Read the Full Text Now for Free!
Difficulty Assessment Summary
We have estimated Сиерра-Морена to have a difficulty score of 100. Here're its scores:
| Measure | Score | |
|---|---|---|
| easy difficult | (1 - 100) | |
| Overall Difficulty | 100 | |
| Vocabulary Difficulty | 100 | |
| Grammatical Difficulty | 100 |
Vocabulary Difficulty: Breakdown
Vocabulary difficulty: 100%
This score has been calculated based on frequency vocabulary (the top most frequently used words in Russian). It combines various measures of Сиерра-Морена's text analyzed in terms of frequency vocabulary: a plain vocabulary score, frequency-weighted vocabulary score, banded frequency vocabulary scores based on vocabulary of the text falling in the top 1,000 or 2,000 most frequent words, etc. Here's a further breakdown of how often the top most frequently used words in Russian appear in the full text of Сиерра-Морена:
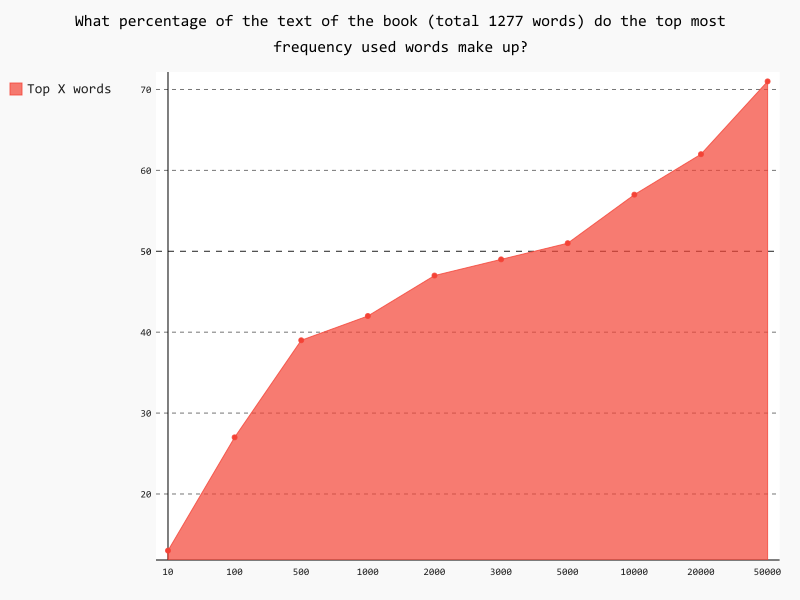
We have also calculated the following approximate data on the vocabulary in Сиерра-Морена:
| Measure | Score |
|---|---|
| Measure | Score |
| Number of words | 1,277 |
| Number of unique words | 840 |
| Number of recognized words for names/places/other entities | 66 |
| Number of very rare non-entity words | 128 |
| Number of sentences | 99 |
| Average number of words/sentence | 13 |
There is some research suggesting that that you need to know about 98% of a text's vocabulary in order to be able to infer the meaning of unknown words when reading. If true, this means that you would need to know around 823 words (where all the forms of the word are still counted as unique words) in Russian to be able to read Сиерра-Морена without a dictionary and fully understand it.
Grammatical Difficulty: Breakdown
Grammatical difficulty: 100%
Here is the further grammatical comparison on this text. You can find an explanation of all these scores below.
| Measure | Score |
|---|---|
| Measure | Score |
| Automated Readability Index | 12 |
| Coleman-Liau Index | 16 |
| Type/Token Ratio (TTR) | 0.657792 |
| Root type/Token Ratio (RTTR) | 0.000515107 |
| Corrected type/Token Ratio (CTTR) | 0.000257554 |
| MTLD Index | 302 |
| HDD Index | 81 |
| Yule's I Index | 151 |
| Lexical Diversity Index (MTLD + HD-D + Yule's I) | 178 |
The type-token ratio (TTR) of Сиерра-Морена is 0.657792. The TTR is the most basic measure of lexical diversity. To calculate it, we divide the number of unique words by the number of words in the text. For example, for this text, the number of unique words is 840, while the number of words is 1,277, so the TTR is 840 / 1,277 = 0.657792. However, the TTR is a very crude measure, as it is extremely dependent on text length. The longer the text, the lower the TTR is usually going to be, since common words tend to often repeat. Especially since the number of words in this text is more than 1,000, the TTR is not likely to give an accurate measure.
The root type-token ratio (RTTR) and corrected type-token ratio (CTTR) are measures which were suggested by researchers to partially address the problem of TTR's variance on text length. In the RTTR, the number of unique words is divided by a square of the number of words (therefore, 840 / (1,277 * 1,277) = 0.000515107), while in CTTR, it is divided by a square of the number of words, multiplied twice 840 / 2 * (1,277 * 1,277) = 0.000257554). However, these measures are not as easily readable, and also there is a growing body of research asserting that CTTR and RTTR do not effectively address the problems of text length. Therefore, while we do provide the full text's TTR, RTTR and CTTR on this page, these fiqures do not form part of our final calculations.
The Automated Readability Index (ARI) is one readability measure that has been developed by researchers over the years. The formula for calculating the ARI is as follows: 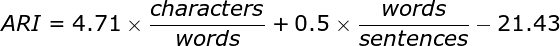
The ARI should compute a reading level approximately corresponding to the reader's grade level (assuming the reader undertakes formal education). Thus, for example, a value of 1 is kindergarten level, while a value of 12 or 13 is the last year of school, and 14 is a sophomore at college. The current ARI of this text is 12, making it understandable for 12-grade students at their expected level of education.
The Coleman Liau Index (CLI) is a similar index designed by Meri Coleman and T. L. Liau, and it is supposed to compute the grade level of the reader (thus, for example, sophomore level material would be around grade 14, or year 14 of formal education, while kindergarten / primary school level material would be close to grade 1 in the CLI). The CLI is usually slightly higher than the ARI. The CLI is computed with this formula:
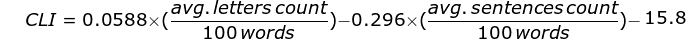
It is notable that other indexes exist, such as the Flesch-Kincaid Reading Ease, Gunning-Fog Score, and others, but we have chosen not to include them, since, contrary to the ARI and CLI, such other indexes are based on a syllable count and therefore arguably only work for English and not Russian.
We compute a further compound lexical diversity index, which should range from 1 to a 100 (with the standard deviation being around 10, and its average value being around 50) - it is 178 in the present case. The compound lexical diversity index consists of the following indexes, averaged out (and also provided in the table above):
- the Measure of Textual Lexical Diversity (MTLD) index - a measure which is based on computing the TTR for increasingly larger parts of the text until the TTR drops below a certain threshold point (around 0.7 in our case) - in which case, the TTR is reset, and the overall counter is increased; the counter is at the end divided by the number of words in text; as a result, the MTLD does not significantly vary by text length;
- the Yule's I index (based on Yule's K characteristic inverted) - an index based on the work of the statistician G.U. Yule, who published his index of Frequency Vocabulary in his paper "The statistical study of literary vocabulary"; Yule's I takes into account the number of words in the text, and a compound summed measure of word frequency;
- the Hypergeometric Distribution D (HD-D) index (based on vocd) - an index which assesses the contribution of each word to the diversity of the text; to calculate such contributions, a hypergeometric distribution is used to compute probabilities of each word appearing in word samples extracted from the text; then such distributions are divided by sample sizes and added up;
Our overall measure of grammatical diversity is based on a combination of the compound lexical diversity index (which includes the MTLD, Yule's I and HD-D indexes), the ARI and CLI, all normalized and given certain weight. The score should normally range from 1 to 100. In this case, the score is 100.
Other Information about Сиерра-Морена by Николай Карамзин
We provide you a sample of the text below, however, the full text of the Сиерра-Морена is also available free of charge on our website.
Sample of text:
Небо страшно наказало клятвопреступницу, -сказала мне Эльвира, - я убийца Алонзова! Кровь его палит меня. Удались отнесчастной! Земля расступилась между нами, и тщетно будешь простирать ко мнеруки свои! Бездна разделила нас навеки. Можешь только взорами своимирастравлять неизлечимую рану моего сердца. Удались от несчастной! Моя горесть, мое отчаяние не могли тронуть ее - Эльвира погребланесчастного Алонза на том месте, где оплакивала некогда мнимую смерть его, изаключилась в строжайшем из женских монастырей. Увы! Она не хотелапроститься со мною!.. Не хотела, чтобы я в последний раз обнял ее со всеюгорячностию любви и видел в глазах ее хотя одно сожаление о моей участи! Я был в исступлении - искал в себе чувствительного сердца, но сердце,подобно камню, лежало в груди моей - искал слез и не находил их - мертвое,страшное уединение окружило меня. День и ночь слились для глаз моих в вечный сумрак. Долго не знал я нисна, ни отдохновения, скитался по тем местам, где бывал вместе - с жестокоюи несчастною; хотел найти следы, остатки, части моей Эльвиры, напечатлониядуши ее... Но хлад и тьма везде меня встречали! Иногда приближался я к уединенным стенам того монастыря, гдезаключилась неумолимая Эльвира: там грозные башни возвышались, железныезапоры на вратах чернелись, вечное безмолвие обитало, и какой-то унылыйголос вещал мне: Для тебя уже нет Эльвиры! Наконец я удалился от Сиерры-Moрены - оставил Андалузию, Гишпанию,Европу, - видел печальные остатки древней Пальмиры, некогда славной ивеликолепной, - и там, опершись на развалины, внимал глубокой, красноречивойтишине, царствующей в сем запустении и одними громами прерываемой. Там, вобъятиях меланхолии, сердце мое размягчилось, - там слеза моя оросила сухоетление, - там, помышляя о жизни и смерти народов, живо восчувствовал я суетувсего подлунного и сказал самому себе: Что есть жизнь человеческая? Чтобытие наше? ...
Top most frequently used words in Сиерра-Морена by Николай Карамзин*
| Position | Word | Repetitions | Part of all words |
|---|---|---|---|
| Position | Word | Repetitions | Part of all words |
| 1 | ее | 20 | 1.57% |
| 2 | на | 18 | 1.41% |
| 3 | Эльвира | 13 | 1.02% |
| 4 | его | 9 | 0.7% |
| 5 | где | 9 | 0.7% |
| 6 | не | 8 | 0.63% |
| 7 | из | 7 | 0.55% |
| 8 | меня | 7 | 0.55% |
| 9 | сердце | 7 | 0.55% |
| 10 | но | 7 | 0.55% |
| 11 | свою | 6 | 0.47% |
| 12 | Эльвиру | 6 | 0.47% |
| 13 | там | 6 | 0.47% |
| 14 | любить | 6 | 0.47% |
| 15 | мои | 6 | 0.47% |
| 16 | моей | 5 | 0.39% |
| 17 | тебя | 5 | 0.39% |
| 18 | все | 5 | 0.39% |
| 19 | сердца | 5 | 0.39% |
| 20 | слезы | 5 | 0.39% |
| 21 | клялась | 5 | 0.39% |
| 22 | он | 5 | 0.39% |
| 23 | мне | 5 | 0.39% |
| 24 | свои | 5 | 0.39% |
| 25 | Она | 5 | 0.39% |
| 26 | мое | 4 | 0.31% |
| 27 | Алонза | 4 | 0.31% |
| 28 | любви | 4 | 0.31% |
| 29 | от | 4 | 0.31% |
| 30 | моих | 4 | 0.31% |
| 31 | хотела | 4 | 0.31% |
| 32 | был | 4 | 0.31% |
| 33 | сказала | 3 | 0.23% |
| 34 | ночь | 3 | 0.23% |
| 35 | Алонзо | 3 | 0.23% |
| 36 | Увы | 3 | 0.23% |
| 37 | себе | 3 | 0.23% |
| 38 | своей | 3 | 0.23% |
| 39 | раз | 3 | 0.23% |
| 40 | для | 3 | 0.23% |
| 41 | их | 3 | 0.23% |
| 42 | груди | 3 | 0.23% |
| 43 | оставил | 3 | 0.23% |
| 44 | день | 3 | 0.23% |
| 45 | моя | 3 | 0.23% |
| 46 | отчаяние | 3 | 0.23% |
| 47 | была | 3 | 0.23% |
| 48 | руку | 3 | 0.23% |
| 49 | как | 3 | 0.23% |
| 50 | долго | 3 | 0.23% |
| 51 | тем | 3 | 0.23% |
| 52 | некогда | 3 | 0.23% |
| 53 | было | 2 | 0.16% |
| 54 | слезами | 2 | 0.16% |
| 55 | наслаждался | 2 | 0.16% |
| 56 | кровь | 2 | 0.16% |
| 57 | сердцем | 2 | 0.16% |
| 58 | Жестокий | 2 | 0.16% |
| 59 | Андалузию | 2 | 0.16% |
| 60 | Эльвирин | 2 | 0.16% |
| 61 | что | 2 | 0.16% |
| 62 | мой | 2 | 0.16% |
| 63 | искал | 2 | 0.16% |
| 64 | жизни | 2 | 0.16% |
| 65 | над | 2 | 0.16% |
| 66 | страсть | 2 | 0.16% |
| 67 | памятник | 2 | 0.16% |
| 68 | своею | 2 | 0.16% |
| 69 | быть | 2 | 0.16% |
| 70 | пламя | 2 | 0.16% |
| 71 | лице | 2 | 0.16% |
| 72 | белую | 2 | 0.16% |
| 73 | вас | 2 | 0.16% |
| 74 | подле | 2 | 0.16% |
| 75 | видел | 2 | 0.16% |
| 76 | душу | 2 | 0.16% |
| 77 | ли | 2 | 0.16% |
| 78 | Наконец | 2 | 0.16% |
| 79 | вам | 2 | 0.16% |
| 80 | никого | 2 | 0.16% |
| 81 | Эльвиры | 2 | 0.16% |
| 82 | по | 2 | 0.16% |
| 83 | очах | 2 | 0.16% |
| 84 | остатки | 2 | 0.16% |
| 85 | того | 2 | 0.16% |
| 86 | есть | 2 | 0.16% |
| 87 | стремление | 2 | 0.16% |
| 88 | вечный | 2 | 0.16% |
| 89 | уже | 2 | 0.16% |
| 90 | безмолвие | 2 | 0.16% |
| 91 | исступлении | 2 | 0.16% |
| 92 | вечно | 2 | 0.16% |
| 93 | Европу | 2 | 0.16% |
| 94 | Ах | 2 | 0.16% |
| 95 | сказал | 2 | 0.16% |
| 96 | одно | 2 | 0.16% |
| 97 | твой | 2 | 0.16% |
| 98 | горесть | 2 | 0.16% |
| 99 | вместе | 2 | 0.16% |
| 100 | со | 2 | 0.16% |
| 101 | еще | 2 | 0.16% |
| 102 | Майорки | 2 | 0.16% |
| 103 | хотел | 2 | 0.16% |
| 104 | или | 2 | 0.16% |
| 105 | храма | 2 | 0.16% |
| 106 | Алонзова | 2 | 0.16% |
| 107 | нами | 2 | 0.16% |
| 108 | глазах | 2 | 0.16% |
| 109 | мною | 2 | 0.16% |
| 110 | между | 2 | 0.16% |
| 111 | Сия | 2 | 0.16% |
| 112 | небесные | 2 | 0.16% |
| 113 | навеки | 2 | 0.16% |
| 114 | первый | 2 | 0.16% |
| 115 | свое | 2 | 0.16% |
| 116 | розы | 2 | 0.16% |
| 117 | своих | 2 | 0.16% |
| 118 | урну | 2 | 0.16% |
| 119 | нас | 2 | 0.16% |
| 120 | Удались | 2 | 0.16% |
| 121 | моего | 2 | 0.16% |
| 122 | люблю | 2 | 0.16% |
| 123 | Эльвирином | 2 | 0.16% |
| 124 | сем | 2 | 0.16% |
| 125 | погиб | 2 | 0.16% |
| 126 | любила | 2 | 0.16% |
| 127 | своим | 2 | 0.16% |
| 128 | плыл | 2 | 0.16% |
| 129 | незнакомец | 2 | 0.16% |
| 130 | они | 2 | 0.16% |
| 131 | таил | 2 | 0.16% |
| 132 | черной | 2 | 0.16% |
| 133 | опершись | 2 | 0.16% |
| 134 | могли | 1 | 0.08% |
| 135 | оросила | 1 | 0.08% |
| 136 | замке | 1 | 0.08% |
| 137 | мешаться | 1 | 0.08% |
| 138 | волнах | 1 | 0.08% |
| 139 | приближался | 1 | 0.08% |
| 140 | любезной | 1 | 0.08% |
| 141 | катит | 1 | 0.08% |
| 142 | месте | 1 | 0.08% |
| 143 | систему | 1 | 0.08% |
| 144 | расступилась | 1 | 0.08% |
| 145 | Оно | 1 | 0.08% |
| 146 | чувствительного | 1 | 0.08% |
| 147 | рукою | 1 | 0.08% |
| 148 | несчастной | 1 | 0.08% |
| 149 | разозарились | 1 | 0.08% |
| 150 | облаками | 1 | 0.08% |
| 151 | моимотечеством | 1 | 0.08% |
| 152 | живо | 1 | 0.08% |
| 153 | дружба | 1 | 0.08% |
| 154 | говорить | 1 | 0.08% |
| 155 | горестного | 1 | 0.08% |
| 156 | вуединении | 1 | 0.08% |
| 157 | кинжал | 1 | 0.08% |
| 158 | чудесным | 1 | 0.08% |
| 159 | мнимую | 1 | 0.08% |
| 160 | возвышается | 1 | 0.08% |
| 161 | когда | 1 | 0.08% |
| 162 | сгущению | 1 | 0.08% |
| 163 | удержать | 1 | 0.08% |
| 164 | егожаркими | 1 | 0.08% |
| 165 | чернелись | 1 | 0.08% |
| 166 | прекрасную | 1 | 0.08% |
| 167 | уединении | 1 | 0.08% |
| 168 | унылыйголос | 1 | 0.08% |
| 169 | Сиерры | 1 | 0.08% |
| 170 | бурям | 1 | 0.08% |
| 171 | древней | 1 | 0.08% |
| 172 | черный | 1 | 0.08% |
| 173 | живу | 1 | 0.08% |
| 174 | блистал | 1 | 0.08% |
| 175 | явления | 1 | 0.08% |
| 176 | чувствами | 1 | 0.08% |
| 177 | до | 1 | 0.08% |
| 178 | страшно | 1 | 0.08% |
| 179 | Небо | 1 | 0.08% |
| 180 | севера | 1 | 0.08% |
| 181 | исчезнет | 1 | 0.08% |
| 182 | нарушить | 1 | 0.08% |
| 183 | Ты | 1 | 0.08% |
| 184 | радовались | 1 | 0.08% |
| 185 | тихую | 1 | 0.08% |
| 186 | суетувсего | 1 | 0.08% |
| 187 | оживлялись | 1 | 0.08% |
| 188 | собственные | 1 | 0.08% |
This list excludes punctuation or single-letter words, also some different-case repeats of the same words.
If you think the text would be accessible to you, you can read it on our site (click on the cover to access):

Other resources and languages
If you like this analysis, you should have a look at out our lists of Russian short stories and Russian books.
If you like literature as a means to learn languages - please take a look at our project Interlinear Books. We even have a Russian Interlinear book available for purchase.