Пиковая Дама (Pikovaja Dama) by Александр Пушкин (Aleksandr Pushkin): Difficulty Assessment for Russian Learners
How difficult is Пиковая Дама (Pikovaja Dama) for Russian learners? We have performed multiple tests on its full text (freely available here) of approximately 7,288, crunched all the numbers for you and present the results below.
Read the Full Text Now for Free!
Difficulty Assessment Summary
We have estimated Пиковая Дама to have a difficulty score of 85. Here're its scores:
| Measure | Score | |
|---|---|---|
| easy difficult | (1 - 100) | |
| Overall Difficulty | 85 | |
| Vocabulary Difficulty | 82 | |
| Grammatical Difficulty | 87 |
Vocabulary Difficulty: Breakdown
Vocabulary difficulty: 82%
This score has been calculated based on frequency vocabulary (the top most frequently used words in Russian). It combines various measures of Пиковая Дама's text analyzed in terms of frequency vocabulary: a plain vocabulary score, frequency-weighted vocabulary score, banded frequency vocabulary scores based on vocabulary of the text falling in the top 1,000 or 2,000 most frequent words, etc. Here's a further breakdown of how often the top most frequently used words in Russian appear in the full text of Пиковая Дама:

We have also calculated the following approximate data on the vocabulary in Пиковая Дама:
| Measure | Score |
|---|---|
| Measure | Score |
| Number of words | 7,288 |
| Number of unique words | 3,105 |
| Number of recognized words for names/places/other entities | 355 |
| Number of very rare non-entity words | 363 |
| Number of sentences | 519 |
| Average number of words/sentence | 14 |
There is some research suggesting that that you need to know about 98% of a text's vocabulary in order to be able to infer the meaning of unknown words when reading. If true, this means that you would need to know around 3,042 words (where all the forms of the word are still counted as unique words) in Russian to be able to read Пиковая Дама without a dictionary and fully understand it.
Grammatical Difficulty: Breakdown
Grammatical difficulty: 87%
Here is the further grammatical comparison on this text. You can find an explanation of all these scores below.
| Measure | Score |
|---|---|
| Measure | Score |
| Automated Readability Index | 10 |
| Coleman-Liau Index | 12 |
| Type/Token Ratio (TTR) | 0.426043 |
| Root type/Token Ratio (RTTR) | 0.0000584581 |
| Corrected type/Token Ratio (CTTR) | 0.0000292291 |
| MTLD Index | 148 |
| HDD Index | 75 |
| Yule's I Index | 102 |
| Lexical Diversity Index (MTLD + HD-D + Yule's I) | 108 |
The type-token ratio (TTR) of Пиковая Дама is 0.426043. The TTR is the most basic measure of lexical diversity. To calculate it, we divide the number of unique words by the number of words in the text. For example, for this text, the number of unique words is 3,105, while the number of words is 7,288, so the TTR is 3,105 / 7,288 = 0.426043. However, the TTR is a very crude measure, as it is extremely dependent on text length. The longer the text, the lower the TTR is usually going to be, since common words tend to often repeat. Especially since the number of words in this text is more than 1,000, the TTR is not likely to give an accurate measure.
The root type-token ratio (RTTR) and corrected type-token ratio (CTTR) are measures which were suggested by researchers to partially address the problem of TTR's variance on text length. In the RTTR, the number of unique words is divided by a square of the number of words (therefore, 3,105 / (7,288 * 7,288) = 0.0000584581), while in CTTR, it is divided by a square of the number of words, multiplied twice 3,105 / 2 * (7,288 * 7,288) = 0.0000292291). However, these measures are not as easily readable, and also there is a growing body of research asserting that CTTR and RTTR do not effectively address the problems of text length. Therefore, while we do provide the full text's TTR, RTTR and CTTR on this page, these fiqures do not form part of our final calculations.
The Automated Readability Index (ARI) is one readability measure that has been developed by researchers over the years. The formula for calculating the ARI is as follows: 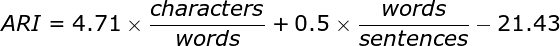
The ARI should compute a reading level approximately corresponding to the reader's grade level (assuming the reader undertakes formal education). Thus, for example, a value of 1 is kindergarten level, while a value of 12 or 13 is the last year of school, and 14 is a sophomore at college. The current ARI of this text is 10, making it understandable for 10-grade students at their expected level of education.
The Coleman Liau Index (CLI) is a similar index designed by Meri Coleman and T. L. Liau, and it is supposed to compute the grade level of the reader (thus, for example, sophomore level material would be around grade 14, or year 14 of formal education, while kindergarten / primary school level material would be close to grade 1 in the CLI). The CLI is usually slightly higher than the ARI. The CLI is computed with this formula:
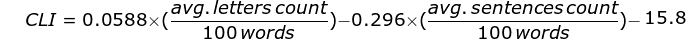
It is notable that other indexes exist, such as the Flesch-Kincaid Reading Ease, Gunning-Fog Score, and others, but we have chosen not to include them, since, contrary to the ARI and CLI, such other indexes are based on a syllable count and therefore arguably only work for English and not Russian.
We compute a further compound lexical diversity index, which should range from 1 to a 100 (with the standard deviation being around 10, and its average value being around 50) - it is 108 in the present case. The compound lexical diversity index consists of the following indexes, averaged out (and also provided in the table above):
- the Measure of Textual Lexical Diversity (MTLD) index - a measure which is based on computing the TTR for increasingly larger parts of the text until the TTR drops below a certain threshold point (around 0.7 in our case) - in which case, the TTR is reset, and the overall counter is increased; the counter is at the end divided by the number of words in text; as a result, the MTLD does not significantly vary by text length;
- the Yule's I index (based on Yule's K characteristic inverted) - an index based on the work of the statistician G.U. Yule, who published his index of Frequency Vocabulary in his paper "The statistical study of literary vocabulary"; Yule's I takes into account the number of words in the text, and a compound summed measure of word frequency;
- the Hypergeometric Distribution D (HD-D) index (based on vocd) - an index which assesses the contribution of each word to the diversity of the text; to calculate such contributions, a hypergeometric distribution is used to compute probabilities of each word appearing in word samples extracted from the text; then such distributions are divided by sample sizes and added up;
Our overall measure of grammatical diversity is based on a combination of the compound lexical diversity index (which includes the MTLD, Yule's I and HD-D indexes), the ARI and CLI, all normalized and given certain weight. The score should normally range from 1 to 100. In this case, the score is 87.
Other Information about Пиковая Дама by Александр Пушкин
We provide you a sample of the text below, however, the full text of the Пиковая Дама is also available free of charge on our website.
Sample of text:
– Старая ведьма! – сказал он, стиснув зубы, – так я ж заставлю тебя отвечать... С этим словом он вынул из кармана пистолет. При виде пистолета графиня во второй раз оказала сильное чувство. Она закивала головою и подняла руку, как бы заслоняясь от выстрела... Потом покатилась навзничь... и осталась недвижима. – Перестаньте ребячиться, – сказал Германн, взяв её руку. – Спрашиваю в последний раз: хотите ли назначить мне ваши три карты? – да или нет? Графиня не отвечала. Германн увидел, что она умерла. IV 7 Mai 18**. Homme sams mceurs et sans religion! Переписка. Лизавета Ивановна сидела в своей комнате, ещё в бальном своём наряде, погружённая в глубокие размышления. Приехав домой, она спешила отослать заспанную девку, нехотя предлагавшую ей свою услугу, – сказала, что разденется сама, и с трепетом вошла к себе, надеясь найти там Германна и желая не найти его. С первого взгляда она удостоверилась в его отсутствии и благодарила судьбу за препятствие, помешавшее их свиданию. Она села, не раздеваясь, и стала припоминать все обстоятельства, в такое короткое время и так далеко её завлёкшие. Не прошло и трёх недель с той поры, как она в первый раз увидела в окошко молодого человека, – и уже она была с ним в переписке, – и он успел вытребовать от неё ночное свидание! Она знала имя его потому только, что некоторые из его писем были им подписаны; никогда с ним не говорила, не слыхала его голоса, никогда о нём не слыхала... до самого сего вечера. Странное дело! В самый тот вечер, на бале, Томский, дуясь на молодую княжну Полину ***, которая, против обыкновения, кокетничала не с ним, желал отомстить, оказывая равнодушие: он позвал Лизавету Ивановну и танцевал с нею бесконечную мазурку. Во всё время шутил он над её пристрастием к инженерным офицерам, уверял, что он знает гораздо более, нежели можно было ей предполагать, и некоторые из его шуток были так удачно направлены, что Лизавета Ивановна думала несколько раз, что её тайна была ему известна. – От кого вы всё это знаете? – спросила она, смеясь. – От приятеля известной вам особы, – отвечал Томский, – человека очень замечательного! – Кто же этот замечательный человек? – Его зовут Германном. Лизавета Ивановна не отвечала ничего, но её руки и ноги поледенели... – Этот Германн, – продолжал Томский, – лицо истинно романтическое: у него профиль Наполеона, а душа Мефистофеля. ...
Top most frequently used words in Пиковая Дама by Александр Пушкин*
| Position | Word | Repetitions | Part of all words |
|---|---|---|---|
| Position | Word | Repetitions | Part of all words |
| 1 | не | 129 | 1.77% |
| 2 | на | 91 | 1.25% |
| 3 | Германн | 82 | 1.13% |
| 4 | что | 78 | 1.07% |
| 5 | его | 72 | 0.99% |
| 6 | её | 65 | 0.89% |
| 7 | он | 61 | 0.84% |
| 8 | она | 59 | 0.81% |
| 9 | за | 42 | 0.58% |
| 10 | Лизавета | 37 | 0.51% |
| 11 | Ивановна | 37 | 0.51% |
| 12 | как | 36 | 0.49% |
| 13 | из | 29 | 0.4% |
| 14 | была | 27 | 0.37% |
| 15 | ему | 26 | 0.36% |
| 16 | но | 25 | 0.34% |
| 17 | то | 25 | 0.34% |
| 18 | графиня | 25 | 0.34% |
| 19 | вы | 24 | 0.33% |
| 20 | же | 23 | 0.32% |
| 21 | было | 23 | 0.32% |
| 22 | мне | 22 | 0.3% |
| 23 | ни | 22 | 0.3% |
| 24 | от | 21 | 0.29% |
| 25 | сказала | 21 | 0.29% |
| 26 | сказал | 20 | 0.27% |
| 27 | по | 20 | 0.27% |
| 28 | это | 19 | 0.26% |
| 29 | вам | 19 | 0.26% |
| 30 | карты | 18 | 0.25% |
| 31 | неё | 18 | 0.25% |
| 32 | Чекалинский | 16 | 0.22% |
| 33 | три | 16 | 0.22% |
| 34 | свою | 16 | 0.22% |
| 35 | уже | 15 | 0.21% |
| 36 | него | 15 | 0.21% |
| 37 | очень | 15 | 0.21% |
| 38 | все | 14 | 0.19% |
| 39 | раз | 14 | 0.19% |
| 40 | Томский | 14 | 0.19% |
| 41 | опять | 13 | 0.18% |
| 42 | меня | 13 | 0.18% |
| 43 | их | 13 | 0.18% |
| 44 | был | 13 | 0.18% |
| 45 | своей | 12 | 0.16% |
| 46 | ли | 12 | 0.16% |
| 47 | ей | 12 | 0.16% |
| 48 | письмо | 11 | 0.15% |
| 49 | для | 11 | 0.15% |
| 50 | бы | 11 | 0.15% |
| 51 | так | 11 | 0.15% |
| 52 | отвечал | 11 | 0.15% |
| 53 | были | 11 | 0.15% |
| 54 | бабушка | 11 | 0.15% |
| 55 | Германна | 11 | 0.15% |
| 56 | стоял | 10 | 0.14% |
| 57 | ним | 10 | 0.14% |
| 58 | ты | 10 | 0.14% |
| 59 | карту | 10 | 0.14% |
| 60 | перед | 10 | 0.14% |
| 61 | над | 10 | 0.14% |
| 62 | всё | 10 | 0.14% |
| 63 | время | 10 | 0.14% |
| 64 | под | 10 | 0.14% |
| 65 | где | 9 | 0.12% |
| 66 | руку | 9 | 0.12% |
| 67 | молодой | 9 | 0.12% |
| 68 | до | 9 | 0.12% |
| 69 | стал | 9 | 0.12% |
| 70 | моя | 9 | 0.12% |
| 71 | отвечала | 9 | 0.12% |
| 72 | семёрка | 9 | 0.12% |
| 73 | Нарумов | 8 | 0.11% |
| 74 | ещё | 8 | 0.11% |
| 75 | человек | 8 | 0.11% |
| 76 | вас | 8 | 0.11% |
| 77 | глаза | 8 | 0.11% |
| 78 | или | 8 | 0.11% |
| 79 | им | 8 | 0.11% |
| 80 | лицо | 8 | 0.11% |
| 81 | руки | 8 | 0.11% |
| 82 | ней | 8 | 0.11% |
| 83 | комнату | 8 | 0.11% |
| 84 | графини | 8 | 0.11% |
| 85 | около | 8 | 0.11% |
| 86 | во | 8 | 0.11% |
| 87 | продолжал | 8 | 0.11% |
| 88 | нет | 7 | 0.1% |
| 89 | только | 7 | 0.1% |
| 90 | кто | 7 | 0.1% |
| 91 | мог | 7 | 0.1% |
| 92 | своего | 7 | 0.1% |
| 93 | дверь | 7 | 0.1% |
| 94 | есть | 7 | 0.1% |
| 95 | лет | 7 | 0.1% |
| 96 | два | 7 | 0.1% |
| 97 | карету | 7 | 0.1% |
| 98 | если | 7 | 0.1% |
| 99 | они | 7 | 0.1% |
| 100 | сидела | 7 | 0.1% |
| 101 | несколько | 7 | 0.1% |
| 102 | туз | 7 | 0.1% |
| 103 | нею | 7 | 0.1% |
| 104 | никогда | 7 | 0.1% |
| 105 | тем | 7 | 0.1% |
| 106 | домой | 7 | 0.1% |
| 107 | Наконец | 7 | 0.1% |
| 108 | улицу | 6 | 0.08% |
| 109 | увидел | 6 | 0.08% |
| 110 | чтоб | 6 | 0.08% |
| 111 | вот | 6 | 0.08% |
| 112 | стала | 6 | 0.08% |
| 113 | минут | 6 | 0.08% |
| 114 | нему | 6 | 0.08% |
| 115 | эту | 6 | 0.08% |
| 116 | люди | 6 | 0.08% |
| 117 | более | 6 | 0.08% |
| 118 | себя | 6 | 0.08% |
| 119 | метать | 6 | 0.08% |
| 120 | тайну | 6 | 0.08% |
| 121 | день | 6 | 0.08% |
| 122 | быть | 6 | 0.08% |
| 123 | человека | 6 | 0.08% |
| 124 | голову | 6 | 0.08% |
| 125 | когда | 6 | 0.08% |
| 126 | Лизанька | 6 | 0.08% |
| 127 | Тройка | 6 | 0.08% |
| 128 | себе | 6 | 0.08% |
| 129 | часов | 6 | 0.08% |
| 130 | после | 6 | 0.08% |
| 131 | сердце | 6 | 0.08% |
| 132 | тихо | 6 | 0.08% |
| 133 | вошёл | 6 | 0.08% |
| 134 | которая | 6 | 0.08% |
| 135 | ничего | 5 | 0.07% |
| 136 | передней | 5 | 0.07% |
| 137 | дома | 5 | 0.07% |
| 138 | со | 5 | 0.07% |
| 139 | остановился | 5 | 0.07% |
| 140 | вошла | 5 | 0.07% |
| 141 | девушки | 5 | 0.07% |
| 142 | Да | 5 | 0.07% |
| 143 | офицер | 5 | 0.07% |
| 144 | одна | 5 | 0.07% |
| 145 | головы | 5 | 0.07% |
| 146 | другой | 5 | 0.07% |
| 147 | комнате | 5 | 0.07% |
| 148 | бедной | 5 | 0.07% |
| 149 | своё | 5 | 0.07% |
| 150 | там | 5 | 0.07% |
| 151 | нибудь | 5 | 0.07% |
| 152 | без | 5 | 0.07% |
| 153 | ко | 5 | 0.07% |
| 154 | них | 5 | 0.07% |
| 155 | дня | 5 | 0.07% |
| 156 | казалось | 5 | 0.07% |
| 157 | может | 5 | 0.07% |
| 158 | Сен | 5 | 0.07% |
| 159 | того | 5 | 0.07% |
| 160 | одной | 5 | 0.07% |
| 161 | свой | 5 | 0.07% |
| 162 | молодого | 5 | 0.07% |
| 163 | об | 5 | 0.07% |
| 164 | налево | 5 | 0.07% |
| 165 | думал | 5 | 0.07% |
| 166 | своём | 5 | 0.07% |
| 167 | окошко | 5 | 0.07% |
This list excludes punctuation or single-letter words, also some different-case repeats of the same words.
If you think the text would be accessible to you, you can read it on our site (click on the cover to access):

Other resources and languages
If you like this analysis, you should have a look at out our lists of Russian short stories and Russian books.
If you like literature as a means to learn languages - please take a look at our project Interlinear Books. We even have a Russian Interlinear book available for purchase.