Деревенская тишь (Derevenskaja tish') by Михаил Салтыков-Щедрин (Mihail Saltykov-Shhedrin): Difficulty Assessment for Russian Learners
How difficult is Деревенская тишь (Derevenskaja tish') for Russian learners? We have performed multiple tests on its full text (freely available here) of approximately 5,848, crunched all the numbers for you and present the results below.
Read the Full Text Now for Free!
Difficulty Assessment Summary
We have estimated Деревенская тишь to have a difficulty score of 79. Here're its scores:
| Measure | Score | |
|---|---|---|
| easy difficult | (1 - 100) | |
| Overall Difficulty | 79 | |
| Vocabulary Difficulty | 90 | |
| Grammatical Difficulty | 68 |
Vocabulary Difficulty: Breakdown
Vocabulary difficulty: 90%
This score has been calculated based on frequency vocabulary (the top most frequently used words in Russian). It combines various measures of Деревенская тишь's text analyzed in terms of frequency vocabulary: a plain vocabulary score, frequency-weighted vocabulary score, banded frequency vocabulary scores based on vocabulary of the text falling in the top 1,000 or 2,000 most frequent words, etc. Here's a further breakdown of how often the top most frequently used words in Russian appear in the full text of Деревенская тишь:

We have also calculated the following approximate data on the vocabulary in Деревенская тишь:
| Measure | Score |
|---|---|
| Measure | Score |
| Number of words | 5,848 |
| Number of unique words | 2,093 |
| Number of recognized words for names/places/other entities | 182 |
| Number of very rare non-entity words | 627 |
| Number of sentences | 271 |
| Average number of words/sentence | 22 |
There is some research suggesting that that you need to know about 98% of a text's vocabulary in order to be able to infer the meaning of unknown words when reading. If true, this means that you would need to know around 2,051 words (where all the forms of the word are still counted as unique words) in Russian to be able to read Деревенская тишь without a dictionary and fully understand it.
Grammatical Difficulty: Breakdown
Grammatical difficulty: 68%
Here is the further grammatical comparison on this text. You can find an explanation of all these scores below.
| Measure | Score |
|---|---|
| Measure | Score |
| Automated Readability Index | 12 |
| Coleman-Liau Index | 11 |
| Type/Token Ratio (TTR) | 0.3579 |
| Root type/Token Ratio (RTTR) | 0.0000612004 |
| Corrected type/Token Ratio (CTTR) | 0.0000306002 |
| MTLD Index | 77 |
| HDD Index | 69 |
| Yule's I Index | 79 |
| Lexical Diversity Index (MTLD + HD-D + Yule's I) | 75 |
The type-token ratio (TTR) of Деревенская тишь is 0.3579. The TTR is the most basic measure of lexical diversity. To calculate it, we divide the number of unique words by the number of words in the text. For example, for this text, the number of unique words is 2,093, while the number of words is 5,848, so the TTR is 2,093 / 5,848 = 0.3579. However, the TTR is a very crude measure, as it is extremely dependent on text length. The longer the text, the lower the TTR is usually going to be, since common words tend to often repeat. Especially since the number of words in this text is more than 1,000, the TTR is not likely to give an accurate measure.
The root type-token ratio (RTTR) and corrected type-token ratio (CTTR) are measures which were suggested by researchers to partially address the problem of TTR's variance on text length. In the RTTR, the number of unique words is divided by a square of the number of words (therefore, 2,093 / (5,848 * 5,848) = 0.0000612004), while in CTTR, it is divided by a square of the number of words, multiplied twice 2,093 / 2 * (5,848 * 5,848) = 0.0000306002). However, these measures are not as easily readable, and also there is a growing body of research asserting that CTTR and RTTR do not effectively address the problems of text length. Therefore, while we do provide the full text's TTR, RTTR and CTTR on this page, these fiqures do not form part of our final calculations.
The Automated Readability Index (ARI) is one readability measure that has been developed by researchers over the years. The formula for calculating the ARI is as follows: 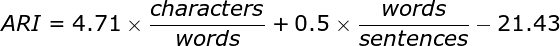
The ARI should compute a reading level approximately corresponding to the reader's grade level (assuming the reader undertakes formal education). Thus, for example, a value of 1 is kindergarten level, while a value of 12 or 13 is the last year of school, and 14 is a sophomore at college. The current ARI of this text is 12, making it understandable for 12-grade students at their expected level of education.
The Coleman Liau Index (CLI) is a similar index designed by Meri Coleman and T. L. Liau, and it is supposed to compute the grade level of the reader (thus, for example, sophomore level material would be around grade 14, or year 14 of formal education, while kindergarten / primary school level material would be close to grade 1 in the CLI). The CLI is usually slightly higher than the ARI. The CLI is computed with this formula:
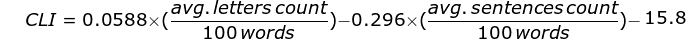
It is notable that other indexes exist, such as the Flesch-Kincaid Reading Ease, Gunning-Fog Score, and others, but we have chosen not to include them, since, contrary to the ARI and CLI, such other indexes are based on a syllable count and therefore arguably only work for English and not Russian.
We compute a further compound lexical diversity index, which should range from 1 to a 100 (with the standard deviation being around 10, and its average value being around 50) - it is 75 in the present case. The compound lexical diversity index consists of the following indexes, averaged out (and also provided in the table above):
- the Measure of Textual Lexical Diversity (MTLD) index - a measure which is based on computing the TTR for increasingly larger parts of the text until the TTR drops below a certain threshold point (around 0.7 in our case) - in which case, the TTR is reset, and the overall counter is increased; the counter is at the end divided by the number of words in text; as a result, the MTLD does not significantly vary by text length;
- the Yule's I index (based on Yule's K characteristic inverted) - an index based on the work of the statistician G.U. Yule, who published his index of Frequency Vocabulary in his paper "The statistical study of literary vocabulary"; Yule's I takes into account the number of words in the text, and a compound summed measure of word frequency;
- the Hypergeometric Distribution D (HD-D) index (based on vocd) - an index which assesses the contribution of each word to the diversity of the text; to calculate such contributions, a hypergeometric distribution is used to compute probabilities of each word appearing in word samples extracted from the text; then such distributions are divided by sample sizes and added up;
Our overall measure of grammatical diversity is based on a combination of the compound lexical diversity index (which includes the MTLD, Yule's I and HD-D indexes), the ARI and CLI, all normalized and given certain weight. The score should normally range from 1 to 100. In this case, the score is 68.
Other Information about Деревенская тишь by Михаил Салтыков-Щедрин
We provide you a sample of the text below, however, the full text of the Деревенская тишь is also available free of charge on our website.
Sample of text:
Ванька, с свойственною ему легкомысленностью, отзывался об этой перемене, что Кондратий Трифоныч спятил; ключница Мавра выражалась скромнее и говорила, что барин задумывается, что на него находит. Как бы то ни было, но перемена существовала и произошла едва ли не в ту самую минуту, как он прочитал, что есть на свете какой-то сословный антагонизм. С тех самых пор он вообразил себе, что он — одна сторона, а Ванька — другая сторона и что они должны бороться. Ванька представлял собою интересы всех чистящих сапоги и топящих печки, Кондратий Трифоныч — интересы всех носящих сапоги и греющихся около истопленных печей. Ясно, что стороны эти не могут понимать друг друга и что из этого должен произойти антагонизм. И вот он борется утром, борется за обедом, борется до поздней ночи. Но Ванька не понимает, что такое антагонизм, и, очевидно, уклоняется от борьбы. Он направляет свои обязанности по-прежнему, то есть по-прежнему не стирает пыли со столов, по-прежнему забывает закрыть трубы в печах, а Кондратий Трифоныч видит во всем грубые мины, злостные позы a la неглиже с отвагой и старается Ваньку изобличить. Из этого выходит, что Ванька, как только забьется в переднюю, первым делом начинает хихикать и представляет, как барин к нему пристает. Кондратий Трифоныч слышит это и говорит: «Ишь, шельма, смеется!», а того никак понять не хочет, что Ванька даже и не подозревает, что ему, Кондратию Трифонычу, хочется борьбы. И таким образом умаявшись к вечеру, оба засыпают; Кондратий Трифоныч видит во сне, что он сделался медведем, что он смял Ваньку под себя и торжествует; Ванька видит во сне, что он третьи сутки все чистит один и тот же сапог и никак-таки вычистить не может. — Что за чудо! — кричит он во сне и как оглашенный вскакивает с одра своего. «Ишь ведь каналья, даже во сне не оставляет в покое!» — думает в это время Кондратий Трифоныч, пробужденный неестественным криком Ваньки. И таким образом проходят дни за днями. Выигрывает от этого положительно один Кондратий Трифоныч, потому что такое препровождение времени, по крайней мере, наполняет пустые дни его. С тех пор как завелось «превосходство вольнонаемного труда над обязательным», с тех пор как, с другой стороны, опекунский совет закрыл гостеприимные свои двери, глуповские веси уныли и запустели. Заниматься решительно нечем, да и не для чего: все равно ничего не выйдет. Говорят, будто это оттого происходит, что кредиту нет и что Сидорычам подняться нечем; может быть, жалоба эта и справедлива, однако до Сидорычей ни в каком случае относиться не может. Недостаток кредита не губит, а спасает их, потому что, будь у них деньги, они накупили бы себе собак, а не то чтоб что-нибудь для души полезное сделать. А то еще подниматься! ...
Top most frequently used words in Деревенская тишь by Михаил Салтыков-Щедрин*
| Position | Word | Repetitions | Part of all words |
|---|---|---|---|
| Position | Word | Repetitions | Part of all words |
| 1 | что | 131 | 2.24% |
| 2 | не | 104 | 1.78% |
| 3 | Трифоныч | 98 | 1.68% |
| 4 | Кондратий | 98 | 1.68% |
| 5 | он | 88 | 1.5% |
| 6 | то | 68 | 1.16% |
| 7 | на | 54 | 0.92% |
| 8 | Ванька | 48 | 0.82% |
| 9 | все | 41 | 0.7% |
| 10 | как | 40 | 0.68% |
| 11 | бы | 36 | 0.62% |
| 12 | ты | 35 | 0.6% |
| 13 | опять | 29 | 0.5% |
| 14 | его | 29 | 0.5% |
| 15 | по | 28 | 0.48% |
| 16 | говорит | 28 | 0.48% |
| 17 | же | 27 | 0.46% |
| 18 | за | 24 | 0.41% |
| 19 | Ну | 24 | 0.41% |
| 20 | это | 24 | 0.41% |
| 21 | ли | 22 | 0.38% |
| 22 | так | 21 | 0.36% |
| 23 | да | 21 | 0.36% |
| 24 | Батюшка | 21 | 0.36% |
| 25 | но | 20 | 0.34% |
| 26 | ни | 19 | 0.32% |
| 27 | еще | 17 | 0.29% |
| 28 | него | 17 | 0.29% |
| 29 | есть | 17 | 0.29% |
| 30 | сам | 16 | 0.27% |
| 31 | думает | 16 | 0.27% |
| 32 | чтоб | 16 | 0.27% |
| 33 | начинает | 15 | 0.26% |
| 34 | во | 15 | 0.26% |
| 35 | только | 14 | 0.24% |
| 36 | вот | 14 | 0.24% |
| 37 | быть | 14 | 0.24% |
| 38 | ему | 14 | 0.24% |
| 39 | мне | 13 | 0.22% |
| 40 | спрашивает | 13 | 0.22% |
| 41 | до | 13 | 0.22% |
| 42 | было | 13 | 0.22% |
| 43 | будет | 12 | 0.21% |
| 44 | Ваньку | 12 | 0.21% |
| 45 | отвечает | 11 | 0.19% |
| 46 | может | 11 | 0.19% |
| 47 | из | 11 | 0.19% |
| 48 | тебе | 11 | 0.19% |
| 49 | нет | 11 | 0.19% |
| 50 | Агашенька | 11 | 0.19% |
| 51 | от | 11 | 0.19% |
| 52 | даже | 10 | 0.17% |
| 53 | другой | 10 | 0.17% |
| 54 | том | 10 | 0.17% |
| 55 | будто | 9 | 0.15% |
| 56 | она | 9 | 0.15% |
| 57 | такое | 9 | 0.15% |
| 58 | ходит | 9 | 0.15% |
| 59 | со | 9 | 0.15% |
| 60 | всех | 9 | 0.15% |
| 61 | этого | 9 | 0.15% |
| 62 | время | 9 | 0.15% |
| 63 | Ладно | 9 | 0.15% |
| 64 | меня | 9 | 0.15% |
| 65 | минуту | 9 | 0.15% |
| 66 | антагонизм | 9 | 0.15% |
| 67 | раз | 8 | 0.14% |
| 68 | себе | 8 | 0.14% |
| 69 | словно | 8 | 0.14% |
| 70 | потому | 8 | 0.14% |
| 71 | образом | 8 | 0.14% |
| 72 | тогда | 8 | 0.14% |
| 73 | пор | 8 | 0.14% |
| 74 | если | 8 | 0.14% |
| 75 | брат | 8 | 0.14% |
| 76 | вдруг | 8 | 0.14% |
| 77 | черт | 7 | 0.12% |
| 78 | объясняет | 7 | 0.12% |
| 79 | буду | 7 | 0.12% |
| 80 | лицо | 7 | 0.12% |
| 81 | можно | 7 | 0.12% |
| 82 | Молчат | 7 | 0.12% |
| 83 | когда | 7 | 0.12% |
| 84 | им | 7 | 0.12% |
| 85 | Трифонычу | 7 | 0.12% |
| 86 | уж | 7 | 0.12% |
| 87 | станового | 7 | 0.12% |
| 88 | один | 7 | 0.12% |
| 89 | восклицает | 6 | 0.1% |
| 90 | кричит | 6 | 0.1% |
| 91 | тут | 6 | 0.1% |
| 92 | день | 6 | 0.1% |
| 93 | батюшке | 6 | 0.1% |
| 94 | который | 6 | 0.1% |
| 95 | своим | 6 | 0.1% |
| 96 | чего | 6 | 0.1% |
| 97 | ничего | 6 | 0.1% |
| 98 | вы | 6 | 0.1% |
| 99 | хочет | 6 | 0.1% |
| 100 | становой | 6 | 0.1% |
| 101 | дома | 6 | 0.1% |
| 102 | того | 6 | 0.1% |
| 103 | видит | 6 | 0.1% |
| 104 | какую | 6 | 0.1% |
| 105 | слегка | 6 | 0.1% |
| 106 | для | 6 | 0.1% |
| 107 | Трифоныча | 6 | 0.1% |
| 108 | чаю | 6 | 0.1% |
| 109 | сне | 6 | 0.1% |
| 110 | думал | 6 | 0.1% |
| 111 | таким | 5 | 0.09% |
| 112 | этом | 5 | 0.09% |
| 113 | под | 5 | 0.09% |
| 114 | дело | 5 | 0.09% |
| 115 | свою | 5 | 0.09% |
| 116 | Сс | 5 | 0.09% |
| 117 | таки | 5 | 0.09% |
| 118 | идет | 5 | 0.09% |
| 119 | свои | 5 | 0.09% |
| 120 | произносит | 5 | 0.09% |
| 121 | их | 5 | 0.09% |
| 122 | выпивает | 5 | 0.09% |
| 123 | месте | 5 | 0.09% |
| 124 | Стало | 5 | 0.09% |
| 125 | приезда | 5 | 0.09% |
| 126 | Москву | 5 | 0.09% |
| 127 | голову | 5 | 0.09% |
| 128 | тех | 5 | 0.09% |
| 129 | более | 5 | 0.09% |
| 130 | себя | 5 | 0.09% |
| 131 | кого | 5 | 0.09% |
| 132 | конечно | 5 | 0.09% |
| 133 | над | 5 | 0.09% |
| 134 | надо | 5 | 0.09% |
| 135 | какой | 5 | 0.09% |
| 136 | сапоги | 5 | 0.09% |
| 137 | молоко | 5 | 0.09% |
| 138 | уже | 5 | 0.09% |
| 139 | ведь | 5 | 0.09% |
| 140 | Кондратия | 5 | 0.09% |
| 141 | Кондратию | 5 | 0.09% |
| 142 | Пыль | 5 | 0.09% |
| 143 | этот | 5 | 0.09% |
| 144 | где | 5 | 0.09% |
| 145 | вследствие | 4 | 0.07% |
| 146 | передней | 4 | 0.07% |
| 147 | сараям | 4 | 0.07% |
| 148 | выходит | 4 | 0.07% |
| 149 | дворе | 4 | 0.07% |
| 150 | левой | 4 | 0.07% |
| 151 | двери | 4 | 0.07% |
| 152 | Ишь | 4 | 0.07% |
| 153 | хочется | 4 | 0.07% |
| 154 | замечает | 4 | 0.07% |
| 155 | хоть | 4 | 0.07% |
| 156 | никак | 4 | 0.07% |
| 157 | вас | 4 | 0.07% |
| 158 | этой | 4 | 0.07% |
| 159 | около | 4 | 0.07% |
| 160 | нибудь | 4 | 0.07% |
| 161 | ней | 4 | 0.07% |
| 162 | рюмку | 4 | 0.07% |
| 163 | торговать | 4 | 0.07% |
| 164 | целый | 4 | 0.07% |
| 165 | дает | 4 | 0.07% |
| 166 | какая | 4 | 0.07% |
| 167 | тик | 4 | 0.07% |
| 168 | наши | 4 | 0.07% |
| 169 | слова | 4 | 0.07% |
This list excludes punctuation or single-letter words, also some different-case repeats of the same words.
If you think the text would be accessible to you, you can read it on our site (click on the cover to access):

Other resources and languages
If you like this analysis, you should have a look at out our lists of Russian short stories and Russian books.
If you like literature as a means to learn languages - please take a look at our project Interlinear Books. We even have a Russian Interlinear book available for purchase.